
- Meta and MBZUAI researchers introduce a structured framework to analyze scaling laws in AI model capacity.
- Investigation focuses on understanding the relationship between model size, training time, and performance.
- Findings challenge conventional wisdom, showcasing the potential of smaller models with enhanced computational resources.
- The research aims to determine if total knowledge scales linearly with model size and identify defining constants of scaling.
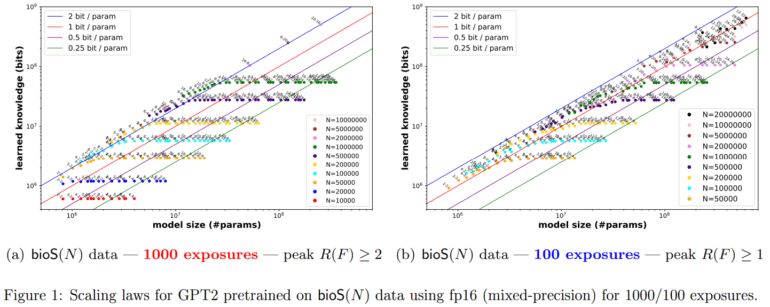
- Language models can store approximately 2 bits of knowledge per parameter, impacting factors include training duration, architecture, quantization, and data quality.
- Introducing domain names to training data significantly augments a model’s knowledge capacity.
- Fully-trained transformer models consistently demonstrate the ability to store 2 bits of knowledge per parameter, regardless of size or other variables.
Main AI News:
Investigating scaling laws for Language and Learning Models (LLMs) is pivotal for understanding the intricate dynamics between model size, training time, and performance. While conventional wisdom dictates the optimal allocation of training resources based on model size, recent studies challenge these assumptions by showcasing the potential of smaller models with enhanced computational resources. Despite strides in comprehending emergent behaviors in large models, there remains a dearth of quantitative analysis on how model size influences its knowledge storage capacity post-training sufficiency. Traditional hypotheses posit that enlarging model size enhances memorization, generalization, and the ability to fit complex functions; however, practical outcomes often diverge due to overlooked variables.
In a collaborative effort between Meta/FAIR Labs and Mohamed bin Zayed University of AI, researchers have unveiled a methodical framework aimed at exploring the precise scaling laws governing the correlation between the size of Language Models (LMs) and their knowledge storage capacity. While the common assumption prevails that larger models inherently possess greater knowledge storage capabilities, this study seeks to ascertain whether total knowledge scales linearly with model size and elucidate the defining constant of this scaling phenomenon. The comprehension of this constant holds paramount importance in evaluating the efficacy of transformer models in knowledge retention and how architectural nuances, quantization techniques, and training durations influence this capacity. By training language models of varying dimensions and defining knowledge in terms of (name, attribute, value) tuples, researchers strive to evaluate knowledge storage efficiency by juxtaposing trainable parameters against the minimum bits requisite for encoding the knowledge.
Language models encode factual knowledge through tuples, with each tuple comprising three distinct strings: name, attribute, and value. The research estimates the quantum of knowledge bits that a language model can accommodate, with findings indicating a consistent capacity of 2 bits of knowledge per parameter. Various factors such as training duration, model architecture, quantization methods, sparsity constraints, and signal-to-noise ratio of data exert notable influences on a model’s knowledge storage capacity. Introducing domain names like wikipedia.org to training data significantly augments a model’s knowledge capacity, empowering it to discern and prioritize domains abundant in information.
Through meticulous inquiry, the researchers underscore a fundamental pattern in scaling laws governing language models: a fully-trained transformer model consistently demonstrates the capability to store 2 bits of knowledge per parameter, irrespective of its size or other variables, including quantization to int8. They delve into the ramifications of different hyperparameters on these scaling laws, encompassing training duration, model architectures, precision, and data quality. This methodological approach furnishes a robust framework for comparing model aptitudes, thereby assisting practitioners in making informed decisions regarding model selection and training. Furthermore, the research lays a solid foundation for tackling the quintessential query pertaining to the optimal size of language models, potentially propelling advancements towards achieving Artificial General Intelligence (AGI).
Conclusion:
The research conducted by Meta and MBZUAI unveils critical insights into AI model capacity, challenging traditional assumptions and highlighting the significance of factors such as model size, training duration, and data quality. These findings have profound implications for the AI market, suggesting that optimizing model size and training methodologies can lead to more efficient and effective AI systems, ultimately driving innovation and competitiveness in the industry.