
- Google Research introduces ‘Patchscopes,’ a framework aimed at interpreting the internal mechanisms of large language models (LLMs).
- Authored by Google researchers, Patchscopes leverages LLMs’ linguistic capabilities to provide natural language explanations of their concealed representations.
- The framework transcends previous limitations in interpretability, offering insights into LLMs’ operations and potential applications in various domains.
- Patchscopes facilitates the detection and rectification of model hallucinations, exploration of multimodal representations, and understanding predictive modeling in complex scenarios.
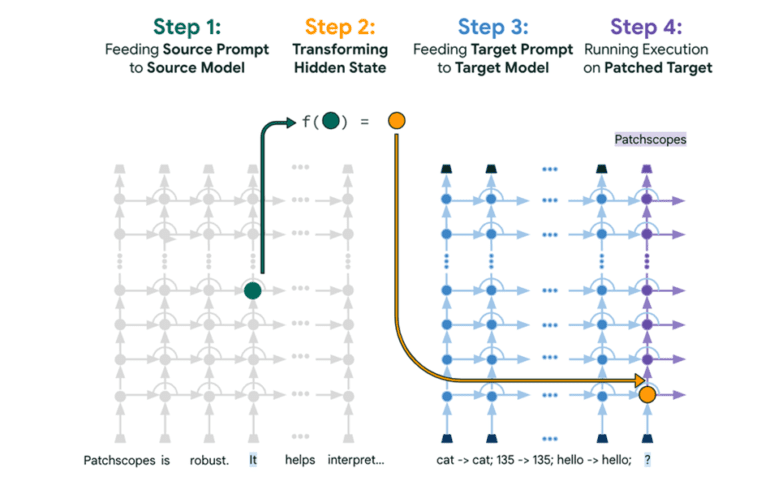
- The configuration involves four steps: Setup, Target, Patch, and Reveal, enabling augmentation of the model’s understanding of context.
Main AI News:
Google Research’s groundbreaking work on ‘Patchscopes’ delves into deciphering the intricate layers of large language models (LLMs). A recent publication introduces Patchscopes, a comprehensive framework that amalgamates various past methodologies aimed at interpreting the inner workings of LLMs. Authored by esteemed Google researchers Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lucas Dixon, and Mor Geva, Patchscopes harnesses the inherent linguistic capabilities of LLMs to provide intuitive, natural language explanations of their concealed internal representations.
This innovative framework not only sheds light on the covert mechanisms of LLMs but also addresses critical questions regarding their operations, thereby transcending the limitations of previous interpretability techniques. Initially tailored for understanding natural language processing within autoregressive Transformer models, Patchscopes exhibits promising potential across diverse applications.
Beyond its primary application in the realm of natural language, Patchscopes harbors broader implications. Researchers foresee its utilization in detecting and rectifying model hallucinations, probing multimodal representations encompassing both images and text and unraveling the intricacies of predictive modeling in complex scenarios.
The configuration of Patchscopes is delineated in four distinct steps: The Setup, The Target, The Patch, and The Reveal. Beginning with a standard prompt presented to the model, a secondary prompt is strategically crafted to extract specific hidden information. Through the process of inference, the hidden representation is injected into the target prompt, enabling the model to scrutinize and augment its understanding of the context, thereby revealing invaluable insights.
While the paper provides a glimpse into the immense potential of Patchscopes, it merely scratches the surface of the opportunities this framework presents. Further research endeavors are imperative to comprehensively gauge its applicability across diverse domains and unlock its full potential.
Conclusion:
The emergence of Google Research’s ‘Patchscopes’ heralds a new era in the interpretability of large language models, offering profound implications for diverse industries. This innovative framework not only enhances our understanding of LLMs’ operations but also opens avenues for addressing challenges such as model hallucinations and multimodal representation exploration. As businesses navigate the evolving landscape of artificial intelligence, Patchscopes stands poised to revolutionize the way we harness the power of language models for enhanced decision-making and innovation.