
TL;DR:
- USC and Microsoft propose UniversalNER, an AI model trained through targeted distillation.
- UniversalNER recognizes over 13,000 entity types, surpassing ChatGPT’s NER accuracy by 9% F1 on 43 datasets.
- Large language models (LLMs) like ChatGPT possess high costs, leading to the rise of instruction tuning for more affordable student models.
- UniversalNER excels in specialized application classes due to mission-focused instruction adjustment.
- The model excels in open information extraction and reproduces LLM capabilities.
- UniversalNER leverages ChatGPT for instruction-tuning data, creating UniNER models for NER.
- UniversalNER benchmark comprises 43 datasets, showcasing its supremacy over Vicuna and ChatGPT in NER accuracy.
- UniversalNER’s victory is by over 30 absolute points against Vicuna and 7-9 absolute points against ChatGPT in F1 accuracy.
- Market implications include improved NER accuracy, efficiency in annotation, and potential for transparent AI decision-making.
Main AI News:
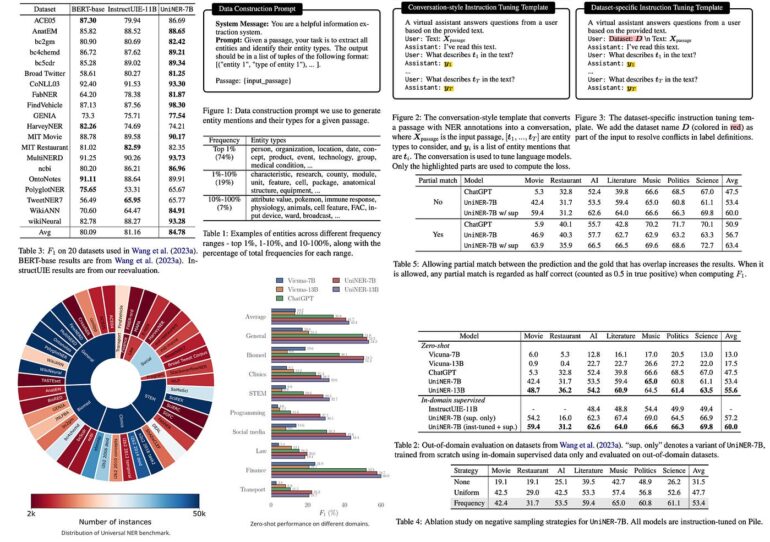
Cutting-edge research from USC and Microsoft introduces a groundbreaking AI innovation that promises to reshape the landscape of Named Entity Recognition (NER). Meet UniversalNER, an AI model that has been meticulously honed through targeted distillation, boasting recognition capabilities across a staggering 13,000+ entity types. This exceptional achievement has propelled UniversalNER to surpass the NER accuracy of ChatGPT by a remarkable 9% F1 on an extensive array of 43 datasets.
In the ever-evolving realm of large language models (LLMs), such as ChatGPT, their prowess in generalized tasks has been indisputable. However, the challenges of exorbitant training and inference costs, coupled with the need for transparent decision-making, have triggered a quest for more efficient and explainable AI solutions. Herein emerges the concept of instruction tuning – a strategic approach to distilling LLMs into streamlined, accessible, and reliable student models. Notably, these refined student models, exemplified by Alpaca and Vicuna, are progressively proving their mettle in emulating the capabilities of their larger counterparts.
Despite these advancements, a persistent gap remains – particularly in application-specific domains. To bridge this divide, researchers delve into the realm of targeted distillation, a paradigm that prioritizes mission-focused instruction adjustment. By concentrating their efforts on diverse application classes, such as open information extraction, they illuminate a path to maximizing the student models’ potential within those specific niches. This nuanced approach empowers UniversalNER to replicate the prowess of LLMs across semantic types and domains, amplifying its prowess for the designated application class.
The chosen battleground for this monumental showdown is named entity recognition (NER), a cornerstone challenge in natural language processing. Recent explorations underline the imperative for LLMs to close the gap when confronted with richly annotated instances. However, the road to mastery isn’t without its hurdles. The creation of annotated examples is a resource-intensive endeavor, especially in specialized domains like biology. Yet, the need to adapt to new emerging entity types remains a driving force.
Enter the transformative synergy of ChatGPT and UniversalNER. In a mesmerizing display of innovation, researchers ingeniously harness ChatGPT’s capabilities to curate instruction-tuning data for NER from vast volumes of unlabeled online text. This dynamic fusion culminates in the birth of UniversalNER models, abbreviated as UniNER, marking a new zenith in NER prowess.
The litmus test for UniNER’s prowess lies in the colossal UniversalNER benchmark – a comprehensive evaluation comprising 43 datasets spanning nine diverse disciplines. This benchmark is a testament to the model’s mettle, encompassing realms as varied as medical, programming, social media, law, and finance. In a captivating showdown, UniNER’s contenders, LLaMA and Alpaca, falter with 0 F1 in zero-shot NER, while Vicuna shines brighter but still trails behind ChatGPT by over 20 absolute points in average F1.
UniversalNER makes an audacious entrance, outshining Vicuna by a staggering 30 absolute points in average F1. It seizes the throne of NER accuracy, reigning supreme across tens of thousands of entity types within the UniversalNER benchmark. Astonishingly, UniversalNER outpaces even ChatGPT’s NER accuracy by a significant margin of 7-9 absolute points in average F1, while also emulating ChatGPT’s prowess with a mere 7-13 billion parameters.
The revelations continue as UniversalNER’s supremacy extends to multi-task instruction-tuned systems, leaving InstructUIE trailing in its wake. A meticulous exploration of UniversalNER’s distillation process, inclusive of instruction prompts and negative sampling, bolsters its credibility, paving the way for further exploration.
Conclusion:
The introduction of UniversalNER stands as a pivotal advancement in the realm of AI-driven Named Entity Recognition. Its targeted distillation approach, coupled with its exceptional accuracy and efficiency gains, marks a substantial leap forward. The market can anticipate improved AI capabilities for NER applications, streamlining resource-intensive annotation processes, and enhancing the transparency of AI systems in critical sectors. This development aligns with the industry’s growing emphasis on accessible, high-precision AI solutions, positioning UniversalNER as a key player in shaping the future of AI-powered information extraction and understanding.