
TL;DR:
- UT Austin researchers introduce MUTEX, a groundbreaking framework for enhancing robot capabilities in human assistance.
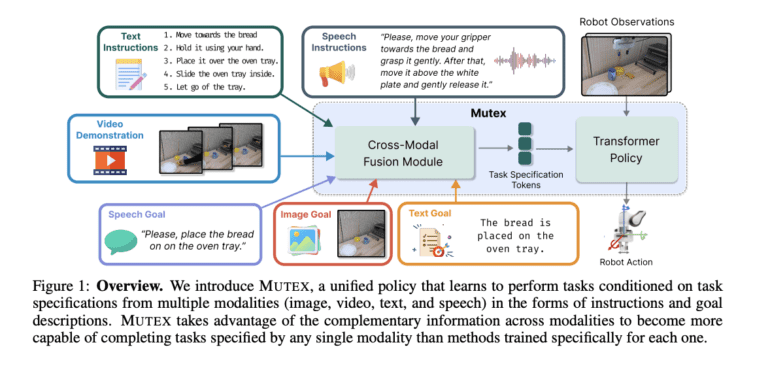
- MUTEX overcomes the limitations of single-modality robotic policy learning, enabling robots to understand and execute tasks through speech, text, images, videos, and more.
- The framework’s two-stage training process combines masked modeling and cross-modal matching, allowing effective information utilization from multiple sources.
- MUTEX’s architecture comprises modality-specific encoders, a projection layer, a policy encoder, and a policy decoder, facilitating seamless integration of task specifications from various modalities.
- Extensive experiments demonstrate significant performance improvements over single-modality methods, with impressive success rates for cross-modal task execution.
- MUTEX holds promise for more effective human-robot collaboration but requires further refinement to address its limitations.
Main AI News:
In a bold stride towards revolutionizing the field of human-robot collaboration, researchers at UT Austin have unveiled MUTEX, an innovative framework designed to empower robots with multifaceted communication abilities. The crux of their endeavor lies in overcoming the inherent limitations of existing robotic policy learning methods, which often cater to just one mode of communication, rendering robots adept in one realm but inept in others.
MUTEX, an acronym for “MUltimodal Task specification for robot EXecution,” takes a giant leap by amalgamating policy learning across multiple modalities. This transformative approach equips robots to not only comprehend but execute tasks based on instructions delivered through a diverse range of mediums, including speech, text, images, videos, and more. This holistic integration marks a pivotal progression towards making robots indispensable collaborators in human-robot partnerships.
The framework’s training methodology comprises a two-stage process. Initially, it employs masked modeling and cross-modal matching objectives. Masked modeling encourages intermodal interactions by obscuring specific tokens or features within each modality, prompting the model to predict them by drawing insights from other modalities. This dynamic ensures that the framework adeptly harnesses information from various sources.
In the second stage, cross-modal matching elevates the representations of individual modalities by aligning them with the features of the most information-rich modality, predominantly video demonstrations in this context. This intricate maneuver guarantees that the framework acquires a shared embedding space that augments the representation of task specifications across diverse modalities.
MUTEX’s architecture boasts modality-specific encoders, a projection layer, a policy encoder, and a policy decoder. It employs modality-specific encoders to distill meaningful tokens from input task specifications. These tokens undergo processing via a projection layer before being transmitted to the policy encoder. Leveraging a transformer-based architecture, the policy encoder fuses insights from various task specification modalities and robot observations. The output is then relayed to the policy decoder, which harnesses a Perceiver Decoder architecture to generate features for action prediction and masked token queries. Distinct MLPs are employed to predict continuous action values and token values for the masked tokens.
To gauge the effectiveness of MUTEX, the researchers meticulously constructed an extensive dataset comprising 100 simulated environment tasks and 50 real-world tasks. Each task was meticulously annotated with multiple instances of task specifications across diverse modalities. The results of their experiments have been nothing short of promising, showcasing substantial performance enhancements in contrast to methods tailored solely for individual modalities. These findings underscore the remarkable potential of cross-modal learning in fortifying a robot’s competence in comprehending and executing tasks. Specifically, Text Goal and Speech Goal achieved a 50.1% success rate, Text Goal and Image Goal boasted a 59.2% success rate, and Speech Instructions and Video Demonstration exhibited an impressive 59.6% success rate.
Conclusion:
MUTEX represents a significant leap in advancing human-robot collaboration capabilities. Its ability to interpret and act upon instructions across diverse modalities holds the potential to revolutionize industries that rely on robotic assistance, from healthcare to manufacturing. As the framework matures and its limitations are addressed, it is poised to transform the market by making robots versatile collaborators in various domains. Businesses that embrace this technology can expect to improve productivity and efficiency in their operations, leading to a competitive edge in the market.