
- Vision Forge introduces a novel framework for training vision models using natural language interactions.
- Traditional computer vision focuses on objective concepts, but real-world applications often require subjective analysis.
- The tool leverages human cognitive processes to break down complex subjective concepts into manageable components.
- By utilizing advancements in large language models and vision-language models, Vision Forge streamlines the process of defining and classifying subjective concepts.
- It requires minimal manual effort, with users only needing to label a small validation set of images.
- Vision Forge outperforms existing methods on subjective tasks and significantly reduces the need for manual annotation.
- This democratization of AI development enables a broader range of users to create customized vision models tailored to their needs.
Main AI News:
In the realm of computer vision, the focus has long been on recognizing universally accepted concepts like animals, vehicles, or specific objects. Yet, the demands of real-world applications often extend beyond these objective realms, requiring the identification of subjective notions that can vary greatly among individuals. Think predicting emotions, evaluating aesthetic appeal, or moderating content – these tasks delve into the subjective spectrum where individual perspectives play a pivotal role.
Consider the definition of “unsafe” content or what qualifies as “gourmet” food; these notions are highly subjective, varying from person to person. Addressing this challenge calls for user-centric training frameworks that enable individuals to train subjective vision models tailored precisely to their criteria.
Enter Agile Vision, a pioneering framework by Agile Modeling, designed to formalize the transformation of any visual concept into a robust vision model. However, existing methodologies often demand extensive manual input and lack efficiency. Take their active learning algorithm, for instance, which mandates users to iteratively label numerous training images, a process that can be both laborious and time-consuming. This inefficiency underscores the urgency for streamlined methods that leverage human capabilities while minimizing manual intervention.
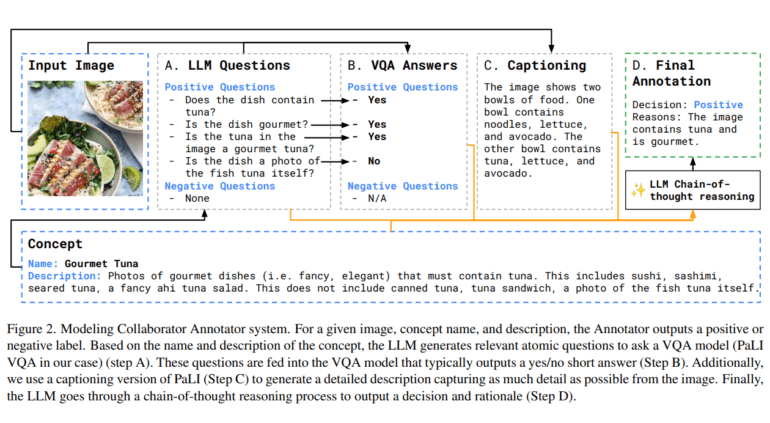
Humans possess a unique ability to break down complex subjective concepts into more digestible and objective components using first-order logic. This cognitive process allows individuals to define intricate ideas effortlessly. Vision Forge harnesses this cognitive prowess, empowering users to construct classifiers by dissecting subjective concepts into their constituent sub-components. This approach significantly diminishes manual effort while enhancing efficiency.
Employing state-of-the-art advancements in large language models (LLMs) and vision-language models (VLMs), Vision Forge simplifies the process of defining and classifying subjective concepts. The system utilizes an LLM to deconstruct concepts into manageable questions for a Visual Question Answering (VQA) model. Users need only label a small validation set of 100 images, drastically reducing the annotation burden.
What sets Vision Forge apart is its unparalleled performance on subjective tasks, particularly on challenging assignments. Unlike previous methods such as Agile Vision, Vision Forge not only outperforms crowd-raters on difficult concepts but also slashes the need for manual annotation by orders of magnitude. By lowering the barriers to model development, Vision Forge accelerates the translation of ideas into reality, ushering in a new era of end-user applications in computer vision.
Moreover, by offering a more accessible and efficient means of building subjective vision models, Vision Forge has the potential to transform AI application development. With reduced manual effort and costs, a broader range of users – including those lacking technical expertise – can participate in creating customized vision models tailored to their requirements. This democratization of AI development holds promise for innovative applications across diverse domains like healthcare, education, and entertainment. Ultimately, by empowering users to swiftly materialize their ideas, Vision Forge drives the democratization of AI, fostering a more inclusive and diverse landscape of AI-powered solutions.
Conclusion:
Vision Forge represents a significant advancement in the field of computer vision, offering a streamlined and efficient approach to building subjective vision models. Its user-centric framework and minimal manual effort requirements have the potential to revolutionize AI application development, making it more accessible and inclusive across various industries. This innovation signals a shift towards democratizing AI development and fostering a more diverse landscape of AI-powered solutions in the market.