
TL;DR:
- WHAM (World-grounded Humans with Accurate Motion) is a pioneering AI approach for precise 3D human motion estimation.
- Developed by researchers from CMU and Max Planck Institute, WHAM addresses challenges in capturing human movement in real-world video.
- It leverages deep learning techniques for model-based 3D human pose and shape recovery, outperforming existing methods.
- WHAM integrates motion context, reduces foot sliding, and offers superior accuracy in per-frame and video-based estimations.
- Evaluation metrics like MPJPE, PA-MPJPE, and PVE confirm WHAM’s excellence.
- Its implications span various industries, from entertainment to healthcare.
Main AI News:
In the intricate realm of 3D human motion estimation, capturing and modeling the intricate movements of individuals in three dimensions poses a formidable challenge. This challenge is amplified when the canvas is set in the real world, where moving cameras introduce complexities such as the vexing issue of foot sliding. Enter WHAM (World-grounded Humans with Accurate Motion), a groundbreaking innovation born from the collaborative efforts of researchers at Carnegie Mellon University and the Max Planck Institute for Intelligent Systems.
WHAM tackles the complexities of 3D human motion reconstruction head-on, making it a noteworthy advancement in this field. To comprehend its significance, let’s delve into the core methodology.
The Landscape of 3D Human Pose and Shape Recovery
The study explores two distinct approaches for the recovery of 3D human pose and shape from images: model-free and model-based. What sets the stage for WHAM’s prowess is its adept use of deep learning techniques, specifically in the realm of model-based methods, where it accurately estimates the parameters of a statistical body model. Traditional video-based 3D Human Pose and Shape (HPS) methods have been known to employ various neural network architectures to incorporate temporal information, while some resort to additional sensors like inertial sensors, albeit intrusively.
WHAM, however, sets a new precedent by seamlessly integrating 3D human motion and video context, effectively harnessing prior knowledge and achieving the precise reconstruction of 3D human activity on a global scale.
Tackling Challenges in Monocular Video
The research diligently addresses the formidable challenges posed by monocular video in accurately estimating 3D human pose and shape. It emphasizes the pivotal aspects of global coordinate consistency, computational efficiency, and the elusive goal of realistic foot-ground contact. Leveraging the invaluable resources of AMASS motion capture and video datasets, WHAM orchestrates a symphony of components to elevate accuracy, even on non-planar surfaces.
The Mechanics of WHAM
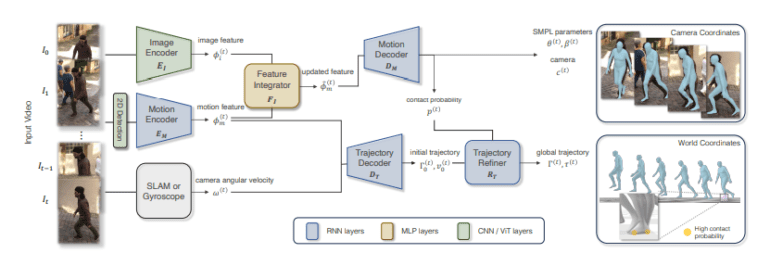
WHAM deploys a unidirectional RNN for online inference, executing precise 3D motion reconstruction with finesse. Its architecture encompasses a motion encoder, vital for context extraction, and a motion decoder that encapsulates SMPL parameters, camera translation, and foot-ground contact probability. A bounding box normalization technique aids in the extraction of motion context. Additionally, the image encoder, pre-trained on human mesh recovery, seamlessly melds image features with motion features through a feature integrator network. A trajectory decoder predicts global orientation and a meticulous refinement process minimizes the vexing issue of foot sliding.
WHAM’s Performance on the Stage
Trained on synthetic AMASS data, WHAM emerges as a formidable player, outperforming existing methods in various evaluations. It boasts superior accuracy in per-frame and video-based 3D human pose and shape estimation, setting a new benchmark in the field. WHAM’s key to success lies in its precise global trajectory estimation, a feat achieved by harnessing motion context and foot contact information. It effectively minimizes foot sliding, fostering international coordination.
Evaluating WHAM’s mettle in the wild, benchmarks confirm its excellence through metrics such as MPJPE, PA-MPJPE, and PVE. Furthermore, the trajectory refinement technique refines global trajectory estimation, demonstrating its prowess in reducing foot sliding, as evidenced by the tangible improvements in error metrics.
Conclusion:
WHAM, a testament to the prowess of AI research, emerges as a transformative force in the realm of 3D human motion estimation. It conquers challenges with finesse, raising the bar for accuracy and efficiency. As the world moves forward, WHAM stands at the forefront, revolutionizing our ability to understand and recreate human motion in three dimensions, with applications spanning from entertainment to healthcare and beyond.