
- Large Language Models (LLMs) face challenges in deciding when to use external tools for tasks like data retrieval and complex calculations.
- Traditional benchmarks assume tool use is always required, which doesn’t reflect real-world uncertainty.
- WTU-Eval, developed by researchers from Beijing Jiaotong University, Fuzhou University, and the Institute of Automation CAS, introduces a new approach to evaluate LLMs’ decision-making on tool usage.
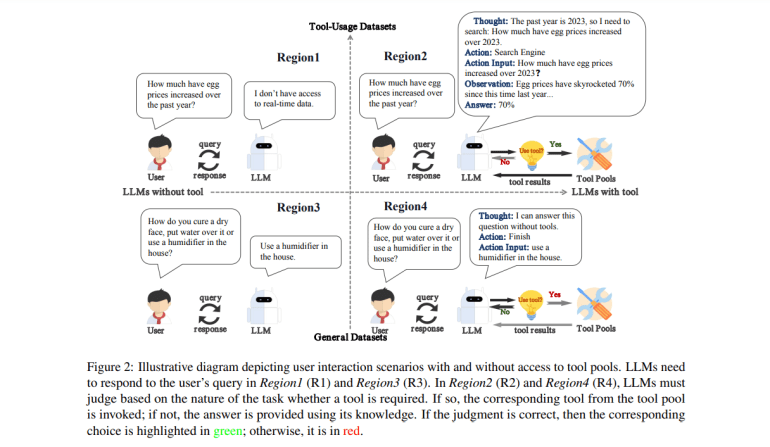
- WTU-Eval includes eleven datasets, six requiring tool use and five general datasets, assessing whether LLMs can accurately determine when tools are necessary.
- A fine-tuning dataset of 4,000 instances derived from WTU-Eval aims to enhance LLMs’ tool usage decisions.
- Evaluation results show varied performance across models, with significant improvements in models like Llama2-7B when fine-tuned.
- Simpler tools are managed better by LLMs compared to complex ones, highlighting the need for improved tool handling in zero-shot settings.
Main AI News:
Large Language Models (LLMs) are increasingly adept at tasks such as text generation, translation, and summarization. Nonetheless, a pressing challenge in natural language processing (NLP) is optimizing how these models interact with external tools to extend their capabilities. This is especially critical in practical applications where LLMs need to access real-time data, perform sophisticated calculations, or interface with APIs to deliver accurate results.
A significant issue is how LLMs decide when to deploy external tools. In practical scenarios, it is often unclear whether a tool is required, and improper use can result in errors and inefficiencies. Addressing this, recent research has focused on improving LLMs’ ability to understand their operational limits and make precise decisions regarding tool usage. This refinement is essential for maintaining the effectiveness and reliability of LLMs in real-world contexts.
Traditionally, enhancing LLMs’ tool usage has involved fine-tuning models for specific tasks where tool utilization is essential. Techniques like reinforcement learning and decision trees have shown promise, particularly in mathematical reasoning and online searches. Existing benchmarks such as APIBench and ToolBench evaluate LLMs’ proficiency with APIs and real-world tools, but they often assume that tool usage is always necessary, not reflecting the uncertainty encountered in actual scenarios.
To address this, researchers from Beijing Jiaotong University, Fuzhou University, and the Institute of Automation CAS introduced the Whether-or-not Tool Usage Evaluation benchmark (WTU-Eval). This benchmark is crafted to assess LLMs’ decision-making flexibility concerning tool use. It features eleven datasets: six requiring tool usage and five general datasets that can be solved without tools. This approach enables a thorough evaluation of whether LLMs can accurately determine when tool usage is warranted. The benchmark encompasses tasks like machine translation, mathematical reasoning, and real-time web searches, offering a comprehensive evaluation framework.
Additionally, the research team developed a fine-tuning dataset of 4,000 instances based on WTU-Eval’s training sets. This dataset aims to enhance LLMs’ decision-making capabilities regarding tool usage. By fine-tuning with this dataset, researchers sought to improve LLMs’ accuracy and efficiency in recognizing when to use tools and incorporating their outputs effectively.
Evaluating eight prominent LLMs with WTU-Eval yielded several insights. Most models struggled with tool usage in general datasets. For example, Llama2-13B’s performance dropped to 0% on some tool-related questions in zero-shot settings, underscoring the difficulties LLMs face in such contexts. However, models showed improved performance in tool-usage datasets, especially when aligned with models like ChatGPT. Fine-tuning Llama2-7B led to a 14% average performance boost and a 16.8% reduction in incorrect tool usage, notably improving in tasks requiring real-time data retrieval and mathematical calculations.
Further analysis revealed varied impacts of different tools on LLM performance. Simpler tools, like translators, were managed more effectively by LLMs, while complex tools, such as calculators and search engines, posed greater challenges. In zero-shot settings, LLM proficiency declined with the complexity of tools. For instance, Llama2-7B’s performance fell to 0% with complex tools in certain datasets, whereas ChatGPT demonstrated significant improvements of up to 25% in tasks like GSM8K when tools were used appropriately.
WTU-Eval’s rigorous evaluation offers valuable insights into LLMs’ tool usage limitations and opportunities for enhancement. Its design, blending tool-use and general datasets, provides a nuanced assessment of models’ decision-making abilities. The success of the fine-tuning dataset in improving performance highlights the importance of targeted training in refining LLMs’ tool usage decisions.
Conclusion:
The introduction of WTU-Eval marks a significant advancement in evaluating LLMs’ tool usage capabilities. This new benchmark provides a more nuanced assessment by incorporating datasets that reflect real-world variability in tool usage. For the market, this means a potential shift towards more sophisticated and accurate evaluations of LLMs, ultimately driving improvements in model performance and reliability. The focus on fine-tuning and the insights gained from varying tool complexities may lead to enhanced LLM applications across diverse industries, addressing current limitations and optimizing operational efficiency.