
TL;DR:
- X-ELM, or Cross-lingual Expert Language Models, addresses the limitations of multilingual models.
- Researchers from esteemed institutions propose training language models separately on specific multilingual data subsets.
- X-ELM aims to reduce inter-language competition for model parameters, preserving efficiency and tailoring proficiency for each language.
- The innovative x-BTM method enhances multilingual data clustering and introduces Hierarchical Multi-Round training for effective knowledge transfer.
- Experiments demonstrate that X-ELM outperforms jointly trained models and adapts to new languages without forgetting previously learned ones.
Main AI News:
Large-scale multilingual language models have become the cornerstone of cross-lingual and non-English Natural Language Processing (NLP) applications. These models are crafted by ingesting copious volumes of text in numerous languages. However, the pervasive challenge lies in the inherent competition for the limited capacity of such models, a conundrum recognized as the ‘curse of multilingualism,’ with the most significant impact on linguistically under-resourced languages.
In a collaborative effort, esteemed researchers from the University of Washington, Charles University in Prague, and the Allen Institute for Artificial Intelligence have proffered an innovative solution – Cross-lingual Expert Language Models (X-ELM). This groundbreaking approach involves the discrete training of language models on specific segments of a multilingual corpus.
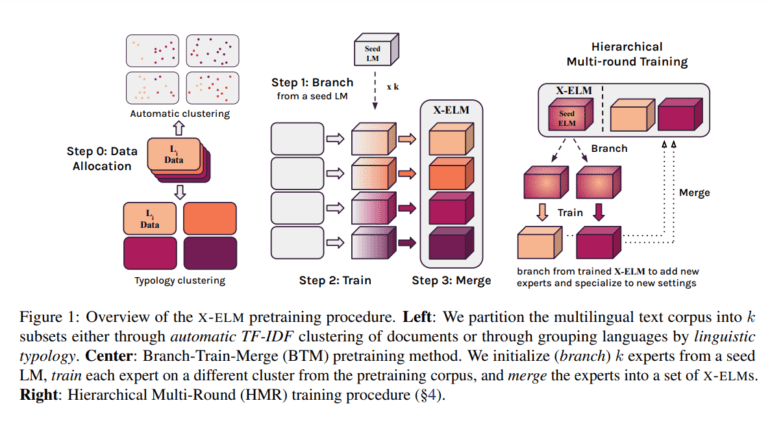
X-ELM’s core objective revolves around mitigating inter-language conflicts for model parameters by affording each language model within the ensemble the autonomy to specialize in a particular subset of the multilingual dataset. The methodology aims to preserve the ensemble’s efficacy while calibrating each model’s proficiency according to a specific language.
The research team’s methodology comprises independent training on distinct subsets of the multilingual corpus for each X-ELM. Employing ensemble techniques has effectively scaled the model’s capacity to more accurately reflect the linguistic diversity within the corpus. Additionally, the team introduces ‘x-BTM,’ an extension of the Branch-Train-Merge (BTM) paradigm, meticulously designed to accommodate the intricate multilingual landscape.
x-BTM bolsters existing BTM methods by introducing a finely-tuned multilingual data clustering approach grounded in typological similarity. Furthermore, it incorporates ‘Hierarchical Multi-Round training’ (HMR), a transformative technique that efficiently imparts specialized knowledge to emerging experts, thereby accommodating previously undiscovered languages and other multilingual data distributions.
The research paper produced by the team unveils the dynamic selection of experts for inference, once the initial X-ELMs have undergone training. Subsequent rounds of x-BTM, with the incorporation of new experts branching from the existing X-ELMs, empower the models to adapt seamlessly to evolving scenarios. This expansion of the X-ELM repertoire does not disrupt the existing experts, thereby ensuring the preservation of previously acquired knowledge.
The experimental phase involved twenty languages, with four additional languages adapted to assess X-ELMs’ performance under varying conditions, compared to dense language models sharing the same computational resources. The observed increases in perplexity across X-ELM languages have been distributed evenly, highlighting the methodology’s robustness. HMR training has proven itself as a superior means of adapting models to novel languages when compared to conventional language-adaptive pretraining techniques.
Empirical studies unequivocally affirm that X-ELM outperforms jointly trained, multilingual models in all languages considered, given equivalent computational resources. This enhancement in performance extends to downstream applications, signifying the model’s practical utility in real-world scenarios. Furthermore, X-ELM’s ability to seamlessly incorporate new languages, without sacrificing proficiency in previously learned ones, underscores its iterative prowess and adaptability within the ensemble.
Conclusion:
The introduction of X-ELM represents a significant advancement in the field of multilingual language models. Its ability to improve performance across languages and adapt to new ones without compromising existing expertise opens up promising opportunities for businesses in diverse linguistic markets. Investing in X-ELM technology can enhance cross-lingual NLP applications, creating a competitive advantage in global markets.