
- Zyphra introduces Zamba2-2.7B, a cutting-edge small language model.
- Trained on a dataset of 3 trillion tokens, it matches the performance of larger models like Zamba1-7B.
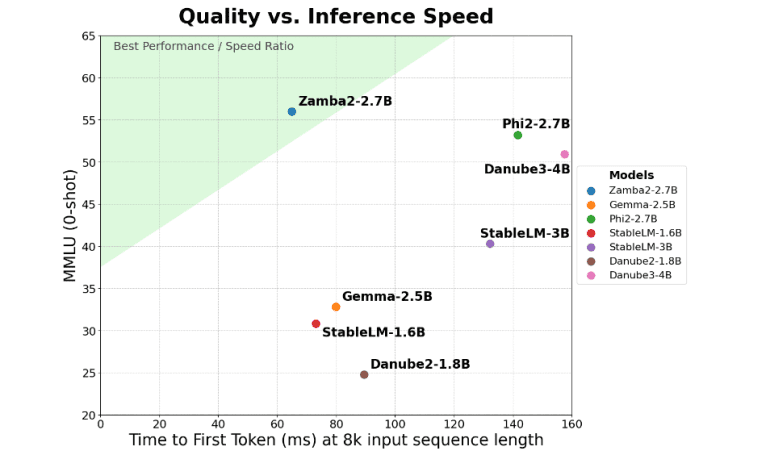
- Delivers twice the speed in time-to-first-token compared to competitors, benefiting real-time applications.
- Reduces memory overhead by 27%, suitable for devices with limited memory.
- Achieves 1.29 times lower generation latency than Phi3-3.8B, enhancing interaction smoothness.
- Consistently outperforms models such as Gemma2-2.7B, StableLM-3B, and Phi2-2.7B in benchmarks.
- Utilizes advanced architecture with an improved attention scheme and Mamba2 blocks for efficient task handling.
Main AI News:
Zyphra’s latest innovation, the Zamba2-2.7B, represents a major leap forward in the realm of small language models, showcasing a remarkable blend of efficiency and performance enhancements. Built upon a dataset of roughly 3 trillion tokens sourced from Zyphra’s proprietary collection, this model rivals the capabilities of larger models such as Zamba1-7B and other prominent 7B variants. Zamba2-2.7B delivers exceptional performance while significantly reducing resource consumption, making it an ideal choice for on-device applications.
One of the standout features of Zamba2-2.7B is its impressive twofold improvement in time-to-first-token, a crucial metric for real-time applications. This advancement enables Zamba2-2.7B to generate initial responses at twice the speed of its competitors, a key factor for virtual assistants, chatbots, and other real-time AI systems where rapid response is critical.
Additionally, Zamba2-2.7B excels in memory efficiency, achieving a 27% reduction in memory overhead. This makes the model particularly suited for deployment on devices with constrained memory resources, ensuring effective operation across various platforms and environments with limited computational capacity.
The model also boasts a notable decrease in generation latency, delivering 1.29 times lower latency compared to Phi3-3.8B. This reduced latency enhances interaction smoothness, which is essential for customer service bots and interactive educational tools that require seamless communication. By maintaining high performance with minimal latency, Zamba2-2.7B positions itself as a prime choice for developers aiming to improve user experience in AI-driven applications.
Benchmark results highlight the exceptional performance of Zamba2-2.7B, consistently outperforming other models of similar scale, including Gemma2-2.7B, StableLM-3B, and Phi2-2.7B. This performance underscores Zyphra’s innovative approach and commitment to pushing the boundaries of AI technology. The model’s advanced architecture, featuring an interleaved shared attention scheme with LoRA projectors and Mamba2 blocks, enhances its ability to handle complex tasks efficiently, delivering high-quality outputs with minimal delays.
Zyphra’s release of Zamba2-2.7B marks a significant milestone in the evolution of small language models. By integrating superior performance with reduced latency and improved memory efficiency, Zamba2-2.7B sets a new benchmark for on-device AI applications, offering a powerful solution for developers and businesses aiming to incorporate advanced AI capabilities into their products.
Conclusion:
Zyphra’s Zamba2-2.7B represents a significant advancement in the small language model market. Its enhanced speed and memory efficiency offer substantial benefits for on-device applications, positioning it as a strong contender for developers seeking high-performance AI solutions. The model’s reduced latency and superior benchmarking performance highlight Zyphra’s innovation and commitment to pushing the boundaries of AI technology. As the demand for efficient and responsive AI applications grows, Zamba2-2.7B sets a new standard for small language models, potentially influencing the market by setting higher expectations for performance and efficiency in AI-driven products.