
- CT-LLM challenges English-centric language models by prioritizing the Chinese language.
- Pre-trained on 1,200 billion tokens, with a strategic emphasis on Chinese data.
- Incorporates innovative techniques like supervised fine-tuning and preference optimization.
- Demonstrates outstanding performance on the Chinese Hard Case Benchmark.
- Represents a significant stride towards inclusive language models reflecting global linguistic diversity.
Main AI News:
The realm of natural language processing has long revolved around models tailored primarily to the English language, inadvertently sidelining a substantial portion of the global populace. However, a transformative development is underway to challenge this entrenched norm and inaugurate an era of inclusivity in language models – enter the Chinese Tiny LLM (CT-LLM).
Envision a scenario where language barriers dissolve, granting seamless access to state-of-the-art AI innovations. This is precisely the vision propelling the creators of CT-LLM, as they champion the Chinese language, one of the most prevalent tongues worldwide. Departing from traditional methodologies, this 2 billion parameter model undergoes meticulous pre-training with a significant focus on Chinese data, a departure from the conventional English-centric approach.
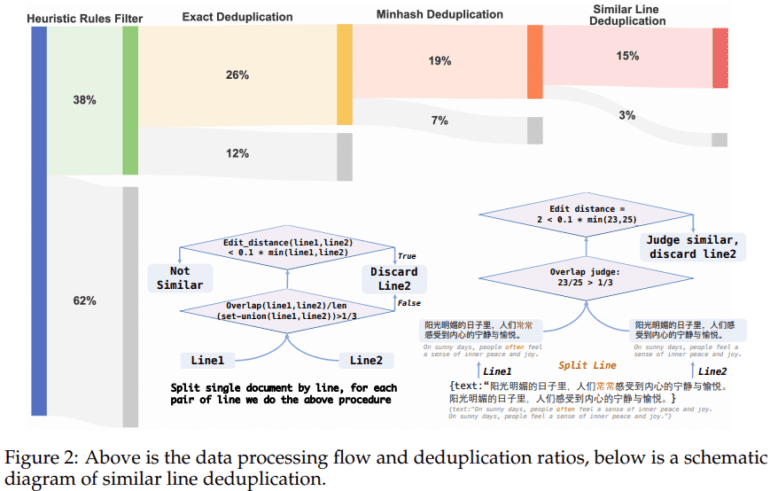
CT-LLM’s pre-training regimen comprises a staggering 1,200 billion tokens, strategically weighted towards Chinese data with 840.48 billion tokens, complemented by 314.88 billion English tokens and 99.3 billion code tokens. This intentional composition not only bolsters the model’s proficiency in Chinese comprehension and processing but also fortifies its adaptability across diverse linguistic landscapes.
Yet, CT-LLM’s prowess extends beyond data composition. It incorporates cutting-edge techniques like supervised fine-tuning (SFT), enhancing its proficiency in Chinese tasks while expanding its repertoire to comprehend and generate English text. Additionally, the integration of preference optimization techniques, including Direct Preference Optimization (DPO), ensures CT-LLM’s outputs align with human preferences, emphasizing accuracy, harmlessness, and utility.
To assess CT-LLM’s capabilities, researchers devised the Chinese Hard Case Benchmark (CHC-Bench), a comprehensive suite of challenges evaluating the model’s proficiency in instruction understanding and execution within the Chinese language domain. Impressively, CT-LLM showcased remarkable performance on this benchmark, particularly excelling in tasks involving social comprehension and written expression, underscoring its nuanced understanding of Chinese cultural nuances.
The advent of CT-LLM signifies a monumental leap towards fostering inclusive language models that mirror the linguistic diversity of our global community. By prioritizing the Chinese language, this pioneering model disrupts the prevailing English-centric paradigm, heralding a future of NLP innovations catering to a myriad of languages and cultures. With its exceptional performance, innovative methodologies, and transparent training process, CT-LLM emerges as a harbinger of an equitable and representative future in natural language processing. In the future, language barriers will fade, paving the way for universal access to cutting-edge AI technologies.
Conclusion:
The emergence of CT-LLM marks a pivotal shift in the language model landscape, signaling a departure from the English-centric paradigm towards a more inclusive approach. By prioritizing the Chinese language and showcasing exceptional performance, CT-LLM sets the stage for future innovations in natural language processing that cater to a broader range of languages and cultures. This presents significant opportunities for businesses operating in diverse linguistic markets, enabling them to leverage advanced AI technologies without language barriers.