
TL;DR:
- LoRAMoE, a plugin version of MoE, addresses the challenge of knowledge erosion in Large Language Models (LLMs).
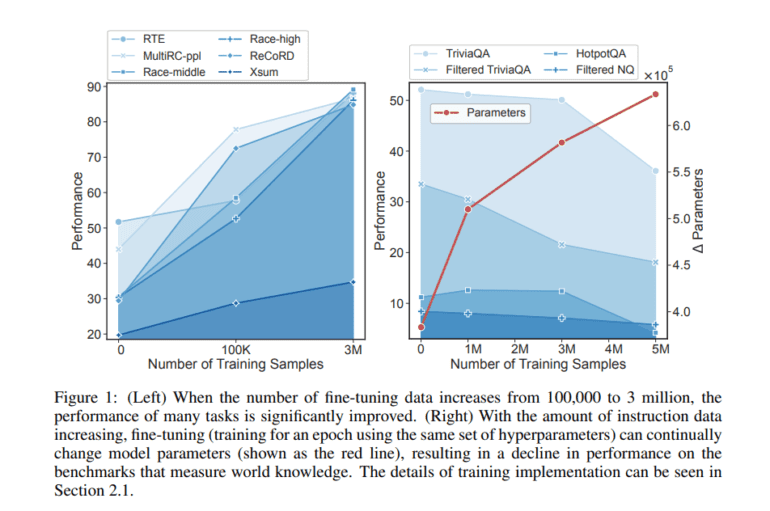
- Large-scale fine-tuning can lead to the loss of world knowledge in LLMs, impacting performance.
- LoRAMoE allocates specific areas of the model to store and utilize global information, akin to the human brain’s memory function.
- Multiple parallel plugins, each specializing in different feed-forward layers, personalize data processing.
- LoRAMoE establishes distinct groups of experts for each layer, balancing the preservation of world knowledge and task enhancement.
- Experimental results show that LoRAMoE effectively retains world information and improves learning across various tasks.
Main AI News:
In the realm of Large Language Models (LLMs), the journey towards harnessing their full potential has been nothing short of transformative. However, as these models continue to evolve and expand their capabilities, a critical challenge has emerged – how to strike the delicate balance between preserving their world knowledge and enhancing performance on a multitude of tasks.
Recent research has shed light on a crucial issue: the significant growth of fine-tuning data can lead to a noticeable decline in performance. This performance drop can be attributed to the erosion of previously acquired world knowledge within the models. But how does this happen?
The answer lies in two key phases. First, LLMs draw inferences from the vast reservoir of world information they have absorbed. Second, during large-scale fine-tuning, the model’s parameters can undergo substantial changes, resulting in what can only be described as “knowledge forgetting.” This dilemma highlights the inherent conflict in vanilla-supervised fine-tuning – the challenge of preserving LLM world information while concurrently enhancing performance on diverse tasks.
In search of a solution, researchers from Fudan University and Hikvision Inc. have introduced LoRAMoE, a groundbreaking plugin version of the “Mixture of Experts” (MoE) architecture. This innovative approach aims to address the knowledge retention issue by allocating specific segments of the model to the storage and utilization of global information, akin to the human brain’s hippocampus, known for its memory function.
LoRAMoE operates on the principle of deploying multiple parallel plugins, each acting as an expert in its respective feed-forward layer. These plugins are equipped to handle data with varying characteristics, ensuring personalized processing. The key to its success lies in creating distinct groups of experts for each LoRAMoE layer while implementing localized balancing constraints. In essence, one group focuses on downstream tasks, while the other is dedicated to preserving world knowledge by aligning human instructions with the model’s stored information. The localized balancing constraint prevents an overemphasis on a select few experts within the same group, fostering collaborative efforts and enhancing task completion capabilities.
Experimental results have provided compelling evidence of LoRAMoE’s effectiveness. It successfully safeguards the world information within language models during large-scale fine-tuning. By visualizing expert weight distribution for tasks, the research team has validated LoRAMoE’s ability to localize capacity at an interpretable level. The results demonstrate that the router assigns priority to experts specializing in world knowledge benchmarks for certain tasks, while concentrating on specialists from a different group for other downstream responsibilities. In essence, LoRAMoE paves the way for expert cooperation, effectively resolving the inherent conflict between knowledge preservation and task enhancement.
Furthermore, the experiments indicate that this innovative strategy enhances learning across various downstream tasks, showcasing its potential for multi-task learning. In conclusion, LoRAMoE represents a significant leap forward in maintaining world knowledge within language models, opening new horizons for the next generation of Large Language Models.
Conclusion:
The introduction of LoRAMoE marks a significant advancement in the world of language models. It addresses the critical issue of knowledge retention, allowing Large Language Models to excel in a broader range of tasks. This innovation has the potential to reshape the market by enabling more efficient and adaptable language models for various industries, from natural language processing to virtual assistants and beyond. LoRAMoE paves the way for improved AI capabilities, offering businesses new opportunities for innovation and enhanced performance in language-related applications.