
TL;DR:
- VITS2, a novel single-stage text-to-speech model, overcomes issues in prior models.
- Improvements focus on naturalness, multi-speaker models, and efficiency.
- Dependence on phoneme conversion is significantly reduced.
- Previous two-stage systems faced challenges in error propagation and complexity.
- Single-stage models excel, generating high-quality human-like speech.
- Prior approaches by Kim, Kong, and Son highlighted challenges to be tackled.
- VITS2 addresses problems, leveraging duration prediction, autoencoders, alignment, and more.
- Experiments on datasets show impressive quality enhancements.
- Proposed methods pave the way for future speech synthesis research.
Main AI News:
In the realm of cutting-edge research, South Korean innovators have unveiled a game-changing solution – VITS2, a single-stage text-to-speech model. This groundbreaking model surmounts prior challenges by revolutionizing multiple dimensions of its predecessors. It effectively conquers hurdles related to intermittent unnaturalness, computational efficiency, and reliance on phoneme conversion. By harnessing ingenious methodologies, VITS2 not only heightens naturalness but also forges a path toward unparalleled efficiency in training and inference.
Shifting from the previous paradigm that heavily leaned on phoneme conversion, VITS2 pioneers a fully end-to-end single-stage methodology, redefining the trajectory of text-to-speech synthesis.
Preceding Approaches: The traditional landscape featured Two-Stage Pipeline Systems, partitioning the waveform generation process from input text into dual cascades. The initial stage engendered intermediary speech representations like mel-spectrograms or linguistic features from the textual input. The ensuing stage then transformed these representations into raw waveforms. Alas, such systems grappled with issues including error amplification between stages, dependence on human-engineered attributes like mel-spectrograms, and the computational overhead of intermediary feature creation.
Enter the Single-Stage Vanguard: Recent strides have been made in Single-Stage Models, which directly translate input text into waveforms. These models have eclipsed the performance of their two-stage counterparts and have even attained the remarkable feat of producing speech almost indistinguishable from human articulation.
A milepost in this trajectory was the Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech, authored by J. Kim, J. Kong, and J. Son. While this pioneering single-stage approach achieved acclaim, it harbored a gamut of challenges – sporadic unnaturalness, suboptimal duration predictor efficiency, intricate input formatting, insufficient speaker resemblance in multi-speaker contexts, languid training, and an overreliance on phoneme conversion.
A Quantum Leap in Progress: This paper’s pièce de résistance lies in addressing the very conundrums that befuddled its precursor, particularly the aforementioned successful model. A symphony of enhancements has been orchestrated, assuring superior quality and efficiency in text-to-speech synthesis.
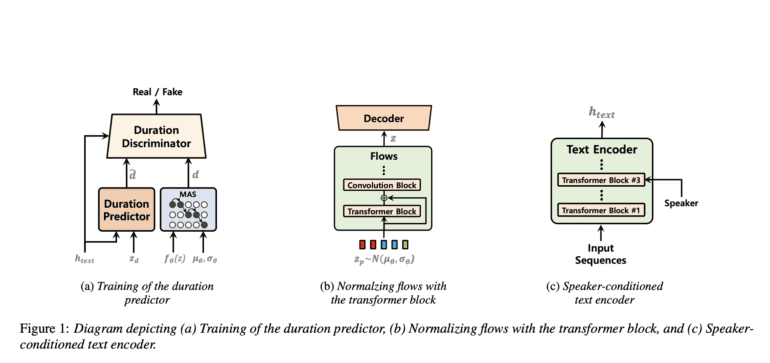
Progress is marked across four domains: Duration Prediction, Augmented Variational Autoencoder Infused with Normalizing Flows, Alignment Search, and Speaker-Conditioned Text Encoder. Proposing a stochastic duration predictor, harnessed through adversarial learning, augments the model’s prowess. Embracing the Monotonic Alignment Search (MAS) in alignment, with tailored modifications, forges a path to improved quality. A transformative touch is witnessed through a transformer block nestled within the normalizing flows, adept at encapsulating long-range dependencies. A bespoke speaker-conditioned text encoder emerges to mirror each speaker’s unique vocal idiosyncrasies.
Validation and Insights: Validation emerges from meticulous experimentation on the LJ Speech and VCTK datasets. Model inputs encompass both phoneme sequences and normalized texts. Training leverages the AdamW optimizer, executed on the powerhouse NVIDIA V100 GPUs. The litmus test of synthesized speech, gauged through crowdsourced Mean Opinion Score (MOS) assessments, accentuates the proposed method’s strides in elevating speech quality. Rigorous ablation studies corroborate the efficacy of the proposed methodologies.
Pinnacle of Success: Concluding with a crescendo of achievement, the authors substantiate their innovations through a tapestry of experiments, quality assessments, and computation velocity benchmarks. Yet, they humbly acknowledge the persisting challenges within the domain of speech synthesis, foreseeing their work as a stepping stone for future explorations. As they beckon towards uncharted horizons, the stage is set for a symphony of advancements in the evolving realm of speech synthesis.
Conclusion:
The introduction of VITS2 marks a pivotal moment in the field of speech synthesis. By addressing key challenges in naturalness, efficiency, and multi-speaker models, VITS2 demonstrates the potential to revolutionize the market. This innovation signifies a significant step forward, not only enhancing the quality of synthesized speech but also laying the foundation for further advancements in speech synthesis technology. As industries increasingly seek more lifelike and efficient speech synthesis solutions, VITS2’s contributions could reshape the landscape and drive market demand for cutting-edge text-to-speech models.