
TL;DR:
- AI language models provide divergent answers to questions due to inherent political biases.
- Research by leading universities identifies varied political tendencies in 14 prominent models.
- OpenAI’s ChatGPT and GPT-4 lean left, while Meta’s LLaMA veers right.
- Testing models on political compass and retraining with biased data confirms and reinforces biases.
- Bias detection affects hate speech and misinformation classification.
- Data cleansing alone is insufficient; AI models can magnify even latent biases.
- The study focuses on older models; applicability to newer ones is uncertain.
Main AI News:
In the realm of artificial intelligence, the question of whether companies should uphold social responsibilities or solely prioritize profit for shareholders has taken center stage. However, the answers you receive from AI systems can be startlingly divergent, contingent on the specific model queried. Former iterations like OpenAI’s GPT-2 and GPT-3 Ada tend to lean towards the former assertion, whereas the more sophisticated GPT-3 Da Vinci, representing the company’s pinnacle achievement, aligns itself with the latter viewpoint.
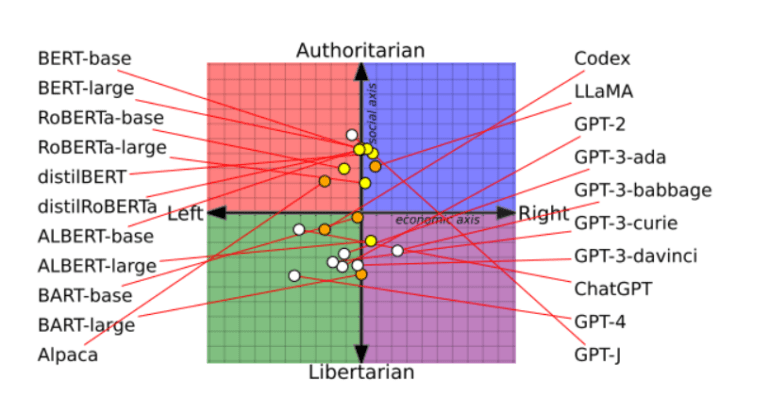
This diversity in AI model perspectives stems from their intrinsic political biases, a revelation borne out of recent research by the University of Washington, Carnegie Mellon University, and Xi’an Jiaotong University. The investigation delved into 14 prominent language models, highlighting OpenAI’s ChatGPT and GPT-4 as the most left-wing libertarian, with Meta’s LLaMA emerging as the epitome of right-wing authoritarianism.
Probing these models about their stance on various topics, from feminism to democracy, facilitated their classification on a political compass. Subsequently, the researchers delved deeper, exploring whether the introduction of more politically biased training data could impact their behavior and their ability to detect hate speech and misinformation – a hypothesis that was proven correct.
Published in a peer-reviewed paper, the study secured the esteemed best paper award at the Association for Computational Linguistics conference. As AI language models find widespread applications among millions, apprehending their foundational political assumptions and biases becomes imperative. The potential harm they wield is substantial, as evidenced by a healthcare advice chatbot’s refusal to address abortion or a customer service bot spewing offensive content.
OpenAI, the creator of ChatGPT, encountered criticism from right-wing observers who perceived the chatbot to harbor a liberal inclination. The company, however, asserts its commitment to resolving such concerns. In a blog post, OpenAI elucidates that its human reviewers, instrumental in fine-tuning AI models, are instructed to remain impartial. Any biases that inadvertently arise are deemed defects, not attributes.
Contrarily, Chan Park, a Carnegie Mellon University PhD researcher, holds that complete immunity from political biases is an unattainable goal. This divergence in perspective originates at each stage of the AI model’s development.
The research team meticulously dissected three development phases to reverse-engineer the acquisition of political biases. First, they prompted 14 language models to concur or dissent on 62 politically nuanced statements. This initial step unveiled the inherent political inclinations of the models, which were then charted on the political compass. Surprisingly, AI models exhibited distinct political tendencies.
BERT models, an AI language model lineage from Google, emerged as more socially conservative than OpenAI’s GPT models. A probable explanation for this contrast lies in their training data; older BERT models were exposed to more conservative texts, whereas newer GPT models drew from the more liberal internet landscape.
Evolution is inevitable in AI models, driven by updates to datasets and training techniques. GPT-2, for instance, expressed support for taxing the wealthy, a sentiment absent in its successor, GPT-3.
Meta, a significant player in the AI field, emphasized transparency in constructing its LLaMA model to minimize bias. OpenAI’s GPT-2 and Meta’s RoBERTa underwent further training on datasets encompassing news and social media from both right- and left-leaning sources. This process unveiled that training data accentuated existing biases, reinforcing left-leaning models’ predisposition and likewise for right-leaning models.
The final phase scrutinized how AI models’ political leanings influenced the categorization of content as hate speech or misinformation. Left-leaning models exhibited heightened sensitivity to hate speech against marginalized groups, whereas right-leaning models identified hate speech targeted at white Christian men. The ability to discern misinformation displayed an analogous pattern.
However, sanitizing datasets of bias alone is inadequate. The endeavor is fraught with challenges due to the vastness of the data and AI models’ penchant for highlighting even latent biases.
One limitation of this study was its focus on relatively older and smaller models like GPT-2 and RoBERTa. The applicability of the findings to newer models such as ChatGPT and GPT-4 remains unverified due to the limited accessibility granted to academic researchers.
The research also acknowledges that while the political compass test is widely used, it does not capture the entirety of political nuances.
Conclusion:
The revelation of diverse political biases ingrained within AI language models underscores a critical challenge for the market. Businesses must recognize the potential implications of these biases as AI models permeate products and services. Ensuring fairness and awareness becomes paramount to avoid inadvertently propagating or amplifying societal biases through these technologies. The findings demand a concerted effort to navigate the nuanced landscape of AI ethics and market dynamics.