
TL;DR:
- Carnegie Mellon University and Honda Research Institute Japan introduce OWSM v3.1, an advanced speech recognition model.
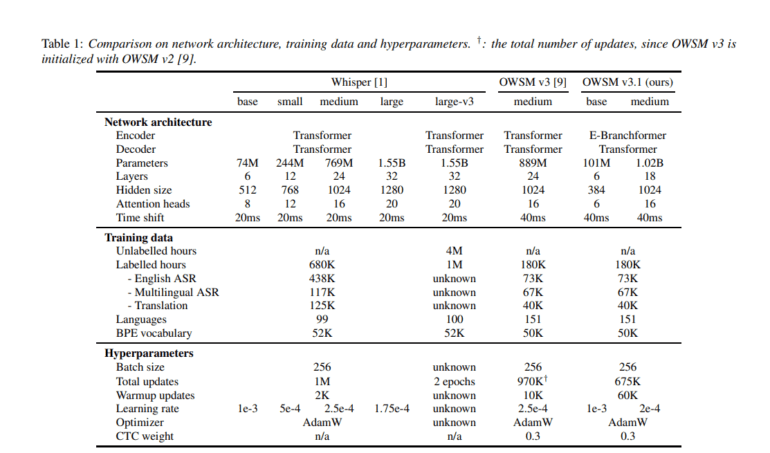
- OWSM v3.1 utilizes the innovative E-Branchformer architecture for improved accuracy and efficiency.
- Excludes WSJ training data, resulting in a significantly lower Word Error Rate (WER).
- Demonstrates up to 25% faster inference speed compared to its predecessor.
- Outperforms OWSM v3 in most evaluation benchmarks, showing improvements in English-to-X translation.
- Marks a significant leap forward in speech recognition technology, offering enhanced precision and adaptability.
Main AI News:
The landscape of speech recognition technology continues to evolve, revolutionizing various applications and industries. In this dynamic field, researchers persistently strive to push boundaries, seeking breakthroughs that enhance accuracy and efficiency across diverse linguistic landscapes. Central to this quest is the challenge of developing models capable of accurately transcribing speech across a spectrum of languages, accents, and environmental conditions.
In response to these imperatives, the Carnegie Mellon University and Honda Research Institute Japan research team has introduced OWSM v3.1, a sophisticated advancement in the realm of speech recognition models. Building upon the formidable legacy of its predecessor, OWSM v3, this latest iteration incorporates the innovative E-Branchformer architecture, poised to deliver unparalleled performance and efficiency.
Traditionally, the realm of speech recognition has grappled with the limitations of existing architectures, often relying on complex frameworks like Transformers. While effective in many respects, these architectures confront challenges in processing speed and grappling with the intricacies of diverse speech patterns, including accents and intonations.
The transformative power of OWSM v3.1 lies in its strategic integration of the E-Branchformer architecture, a cutting-edge approach that promises to redefine the landscape of speech recognition. By leveraging this novel architecture, OWSM v3.1 transcends the constraints of its predecessors, delivering enhanced accuracy and efficiency across a myriad of linguistic contexts.
Key to the efficacy of OWSM v3.1 is its exclusion of the WSJ training data utilized in its predecessor, OWSM v3. This deliberate omission has yielded a substantial reduction in Word Error Rate (WER), underscoring the model’s capacity to discern and interpret speech with unprecedented precision. Moreover, OWSM v3.1 boasts up to 25% faster inference speed, a testament to its streamlined architecture and optimized performance.
In rigorous evaluation benchmarks, OWSM v3.1 has showcased remarkable advancements, surpassing its predecessor across a spectrum of performance metrics. Notably, it excels in English-to-X translation across 9 out of 15 directions, underscoring its versatility and adaptability across diverse linguistic domains. While minor variations may occur in certain directions, the model’s average BLEU score has seen a marginal yet discernible improvement, signaling its enhanced efficacy and robustness.
Conclusion:
The introduction of OWSM v3.1 marks a significant advancement in speech recognition technology, offering enhanced accuracy, efficiency, and versatility. With its superior performance metrics and streamlined architecture, OWSM v3.1 is poised to disrupt the market, empowering businesses with more reliable and efficient speech processing capabilities. This innovation underscores the continued evolution of AI-driven solutions in meeting the growing demands of diverse industries.