
TL;DR:
- CompAgent introduces a groundbreaking approach to text-to-image (T2I) generation.
- It leverages a large language model (LLM) as its core, offering superior controllability.
- CompAgent utilizes a multi-concept customization tool, a layout-to-image generator, and a local image editing tool.
- The agent selects the most suitable tool based on text prompts, ensuring accurate and contextually relevant image outputs.
- CompAgent outperforms previous methods with a 48.63% 3-in-1 metric and over 10% improvement in compositional T2I generation on T2I-CompBench.
Main AI News:
In the ever-evolving realm of computer vision and artificial intelligence, Text-to-Image (T2I) generation is at the forefront, seamlessly blending natural language processing with graphic visualization. This interdisciplinary approach carries immense significance across diverse domains, from digital art and design to the realms of virtual reality.
Numerous methods have emerged for controllable text-to-image generation, with innovations like ControlNet, layout-to-image techniques, and image editing tools making their mark. Large language models (LLMs) such as GPT-4 and Llama have harnessed their prowess in natural language processing, positioning themselves as key players in complex tasks. However, when confronted with intricate scenarios involving multiple objects and their interwoven relationships, these models reveal their limitations, highlighting the pressing need for a more advanced approach to accurately interpret and visualize elaborate textual descriptions.
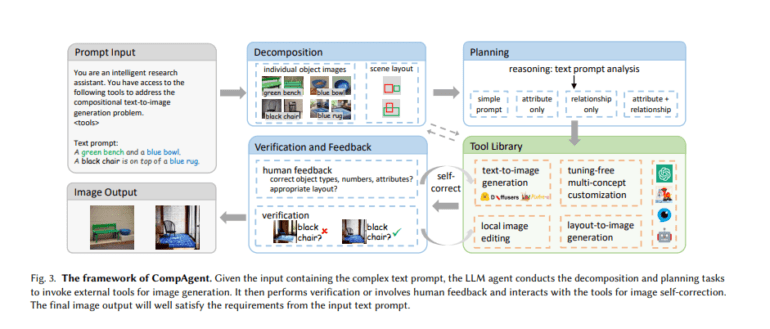
Enter CompAgent, a groundbreaking solution introduced by researchers from Tsinghua University, the University of Hong Kong, and Noah’s Ark Lab. CompAgent leverages an LLM agent at its core for compositional text-to-image generation, and what sets it apart is its strategic “divide-and-conquer” approach. This strategy bolsters controllability in image synthesis, even for the most complex text prompts.
CompAgent employs a tuning-free multi-concept customization tool, drawing from existing object images and input prompts. It incorporates a layout-to-image generation tool to manage intricate object relationships within a scene and a local image editing tool for precise attribute refinement, utilizing segmentation masks and cross-attention editing. The agent intelligently selects the most appropriate tool based on the attributes and relationships embedded within the text prompt. Verification and feedback loops, including human input, play a pivotal role in ensuring attribute accuracy and fine-tuning scene layouts. This comprehensive methodology, which combines a range of tools and verification processes, significantly elevates the capabilities of text-to-image generation, guaranteeing precise and contextually relevant image outputs.
CompAgent has proven its mettle by delivering exceptional performance in generating images that faithfully represent complex text prompts. With a remarkable 48.63% 3-in-1 metric, it surpasses previous methods by a significant margin, exceeding expectations with a more than 7% improvement in compositional text-to-image generation on T2I-CompBench—a benchmark for open-world compositional text-to-image generation. This achievement underscores CompAgent’s prowess in effectively addressing the challenges posed by object types, quantities, attribute bindings, and relationship representations in image generation.

Source: Marktechpost Media Inc.
Conclusion:
CompAgent’s innovative approach to T2I generation has the potential to disrupt various markets, from digital art and design to virtual reality. Its exceptional performance in accurately translating complex textual descriptions into images positions it as a game-changer in the field. Businesses in these sectors can benefit greatly from the enhanced controllability and precision that CompAgent offers, opening up new avenues for creativity and application development.