

- Cornell University researchers introduce the Reinforcement Learning for Consistency Models (RLCM) framework.
- RLCM accelerates text-to-image conversion without compromising quality.
- It leverages reinforcement learning to fine-tune consistency models, optimizing efficiency.
- RLCM achieves training speeds up to 17 times faster and reduces necessary inference steps by 50%.
- Aesthetic evaluation tasks show RLCM improving reward scores by 30% compared to conventional methods.
Main AI News:
In the realm of computer vision, the intersection of textual semantics and visual representation presents a complex landscape with vast potential. From refining digital art to streamlining design processes, the applications are diverse and promising. However, a significant challenge persists: efficiently generating high-quality images aligned with textual prompts.
Recent research has explored foundational diffusion models capable of gradual noise reduction to produce realistic images. Simultaneously, consistency models offer a more direct approach by mapping noise to data, expediting image creation. Despite advancements, these methods often face a trade-off between generation quality and computational efficiency, hindering real-time application.
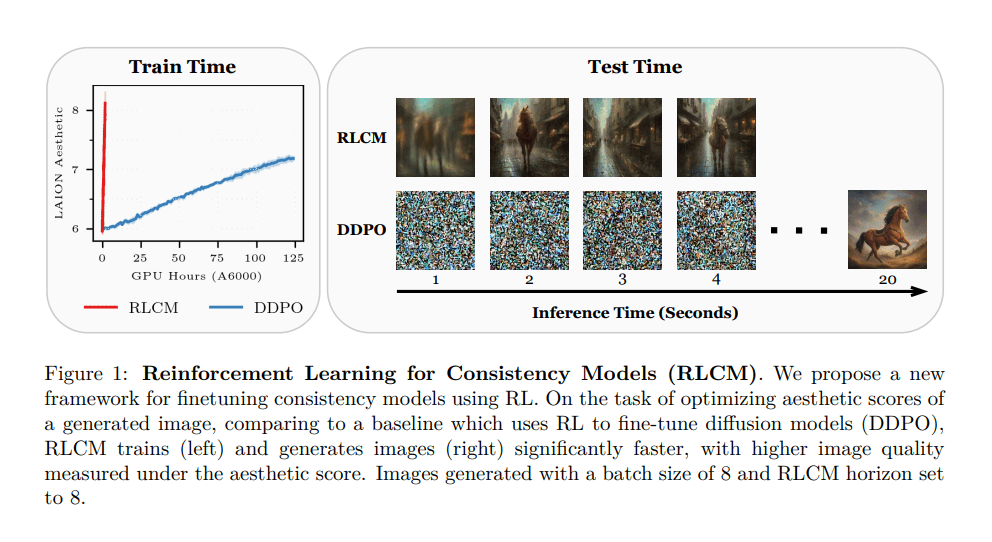
Enter the Reinforcement Learning for Consistency Models (RLCM) framework, pioneered by Cornell University researchers. Departing from iterative refinement, RLCM leverages reinforcement learning to fine-tune consistency models, enabling swift image generation without compromising quality. This novel intervention signifies a remarkable stride towards efficiency and effectiveness in text-to-image conversion.
Source: Marktechpost Media Inc.
RLCM implements a policy gradient approach to refine consistency models, focusing on optimizing the Dreamshaper v7 model. Leveraging datasets such as LAION for aesthetic assessments and a bespoke dataset for image compressibility tasks, RLCM efficiently tailors models for high-quality image generation. By strategically applying RL techniques, RLCM drastically reduces both training and inference times, ensuring effectiveness across varied image generation objectives.
Comparative analysis demonstrates RLCM’s superiority. It achieves training speeds up to 17 times faster than traditional RL fine-tuned diffusion models. In image compressibility tasks, RLCM significantly reduces necessary inference steps by 50%, leading to substantial processing time reductions. Furthermore, RLCM enhances reward scores by 30% in aesthetic evaluation tasks compared to conventional methods.
In summary, RLCM represents a breakthrough in the text-to-image generation landscape, delivering high-quality images efficiently. Its integration of reinforcement learning marks a significant advancement, promising accelerated progress in this domain.

Source: Marktechpost Media Inc.
Conclusion:
Cornell University’s breakthrough in text-to-image generation with the RLCM framework signifies a significant advancement in the market. It promises accelerated image generation processes without sacrificing quality, which could revolutionize industries reliant on computer vision, such as digital art creation, design processes, and more. This innovation opens doors to faster, more efficient workflows, offering businesses a competitive edge in delivering high-quality visual content.