
- DeepMind researchers, along with Yale University and the University of Illinois, propose Naturalized Execution Tuning (NExT).
- NExT improves Large Language Models’ (LLMs) understanding of code execution dynamics.
- The method incorporates detailed runtime data into model training, enhancing semantic understanding.
- NExT utilizes a self-training loop, synthesizing execution traces with proposed code fixes.
- Significant improvements in program repair tasks are observed, with up to 26.1% absolute increase in fix rates.
- The quality of generated rationales for code fixes also sees marked improvement, validated by both automated metrics and human evaluations.
Main AI News:
In the realm of software development, understanding and reasoning about program execution is paramount. DeepMind researchers, in collaboration with Yale University and the University of Illinois, have proposed Naturalized Execution Tuning (NExT), a self-training machine learning method aimed at significantly improving LLMs’ ability to comprehend code execution dynamics.
Historically, developers have relied on mental simulations or debugging tools to navigate program execution and address issues. However, despite their complexity, LLMs trained on code have struggled to grasp the deeper semantic aspects of execution beyond textual representations. This deficiency hampers their performance in tasks such as program repair, where a profound understanding of execution flow is crucial.
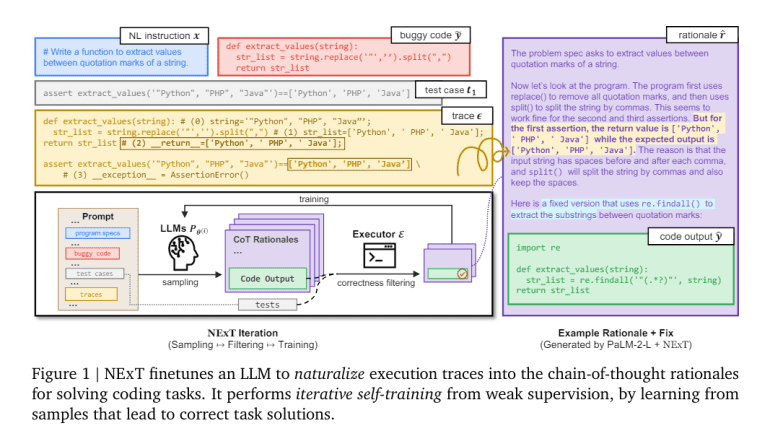
NExT stands out by incorporating detailed runtime data directly into model training, fostering a deeper semantic understanding of code execution. By embedding execution traces as inline comments, NExT enables models to access crucial contexts overlooked by traditional methods, resulting in more accurate and grounded rationales for code fixes.
The methodology of NExT employs a self-training loop, initially synthesizing execution traces with proposed code fixes in a dataset. Leveraging the PaLM 2 model from Google, this approach significantly enhances model accuracy on tasks such as program repair through repeated iterations. Notably, datasets such as Mbpp-R and HumanEval Fix-Plus serve as benchmarks, focusing on practical improvements in LLMs’ programming capabilities without extensive manual annotations.
The efficacy of NExT is evident in substantial improvements in program repair tasks. Upon its application, the PaLM 2 model demonstrated a remarkable 26.1% absolute increase in fix rates on the Mbpp-R dataset and a 14.3% absolute improvement on HumanEval Fix-Plus. These results underscore the enhanced ability of the model to diagnose and rectify programming errors accurately. Furthermore, the quality of generated rationales, crucial for explaining code fixes, saw a marked improvement, validated by both automated metrics and human evaluations.
Conclusion:
The introduction of NExT marks a significant advancement in enhancing the capabilities of Large Language Models in understanding and reasoning about code execution. This innovation has the potential to revolutionize software development by improving the accuracy and efficiency of program repair tasks, ultimately leading to more robust and reliable software systems in the market.