
TL;DR:
- Arizona State University presents ECLIPSE, a novel contrastive learning technique for text-to-image generation.
- Diffusion models excel in producing high-quality images from text, but the computational cost is significant.
- ECLIPSE improves parameter efficiency, reducing model size while maintaining performance.
- It requires only a fraction of image-text pairings and model parameters compared to larger models.
- ECLIPSE outperforms baseline priors, offering a path to more efficient T2I generative models.
- This advancement has significant implications for the market, providing cost-effective solutions for image generation.
Main AI News:
In a recent breakthrough from Arizona State University, researchers have unveiled a cutting-edge advancement in the field of text-to-image generation. Termed “ECLIPSE,” this novel contrastive learning strategy is poised to revolutionize the landscape of non-diffusion priors in the realm of text-to-image transformation.
Diffusion models have garnered acclaim for their ability to produce high-quality images based on textual input. This paradigm, referred to as Text-to-Picture (T2I) production, has found success in various downstream applications, including depth-driven image generation and subject/segmentation identification. Two prominent text-conditioned diffusion models, namely CLIP models and Latent Diffusion Models (LDM), play pivotal roles in these advancements. Notably, LDM, also known as Stable Diffusion, stands out for its open-source availability, while its counterpart, unCLIP models, has largely remained in the shadows.
Both model types share a common objective: to train diffusion models using textual cues. However, the distinction lies in their architectural setup. While unCLIP models integrate a text-to-image prior and a diffusion image decoder, LDM opts for a single text-to-image diffusion model. Both model families operate within the latent space of images quantized as vectors. Given that unCLIP models have demonstrated superiority in composition benchmarks, such as T2I-CompBench and HRS-Benchmark, they take center stage in this article.
These T2I models, characterized by a substantial number of parameters, demand impeccable alignment between images and text during training. In contrast to LDMs, unCLIP models like DALL-E-2, Karlo, and Kandinsky possess a significantly larger model size, surpassing 2 billion parameters due to their previous module, which comprises approximately 1 billion parameters. The training data for these unCLIP models consists of 250 million, 115 million, and 177 million image-text pairs, raising two pivotal questions: 1) Does state-of-the-art performance in text compositions benefit from a text-to-image prior? 2) Or is the augmentation of model size the pivotal factor?
To enhance their understanding of T2I priors, the research team endeavors to augment both parameter and data efficiency, aiming to surpass current formulations. T2I priors, designed to estimate noiseless image embeddings throughout the diffusion process, align with the underlying diffusion models, as indicated by prior research. An empirical investigation into this early dissemination process yielded valuable insights. Notably, the diffusion process exhibited marginal performance degradation and did not significantly impact image generation accuracy. However, it was accompanied by a substantial computational cost, demanding extensive GPU hours or even days. Consequently, the non-diffusion model emerged as a viable alternative in this study. Although this approach may impose limitations on compositional possibilities due to the absence of classifier-guided supervision, it significantly enhances parameter efficiency while reducing data dependencies.
In this study, the Arizona State University research team introduces “ECLIPSE,” a unique contrastive learning technique designed to elevate the T2I non-diffusion prior while mitigating the aforementioned limitations. The team achieves this by optimizing the Evidence Lower Bound (ELBO) in the conventional approach of generating picture embeddings from text embeddings. Additionally, they harness the semantic alignment feature between text and images offered by pre-trained vision-language models to oversee the initial training phase.
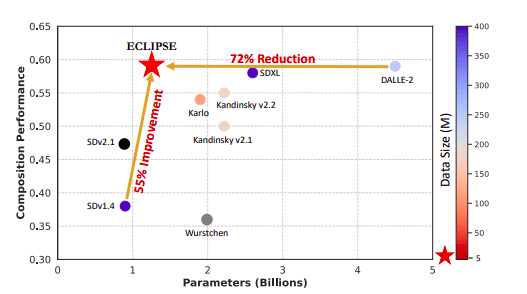
Remarkably, ECLIPSE enables the training of compact non-diffusion prior models, boasting a 97% reduction in size (with 33 million parameters) using a relatively tiny fraction of image-text pairings (0.34% – 8.69%). The research team extends ECLIPSE to the unCLIP diffusion image decoder variations (Karlo and Kandinsky), outperforming their 1 billion parameter counterparts and surpassing baseline prior learning algorithms. This breakthrough paves the way for T2I generative models that enhance compositionality without necessitating an excessive number of parameters or extensive data resources.
Noteworthy contributions of this research include: 1) The introduction of ECLIPSE as the first attempt to utilize contrastive learning for text-to-image priors within the unCLIP framework. 2) The empirical validation of ECLIPSE’s superiority over baseline priors in resource-constrained scenarios is supported by comprehensive experimentation. 3) Remarkably, ECLIPSE priors demonstrate outstanding performance with only 2.8% of the training data and 3.3% of the model parameters compared to larger models. 4) Additionally, the research team delves into the limitations of current T2I diffusion priors and offers valuable empirical observations.
Conclusion:
The introduction of ECLIPSE by Arizona State University signals a pivotal moment in the text-to-image generation market. This innovative technique not only enhances efficiency by reducing model size and data requirements but also outperforms existing solutions. This means cost-effective and high-quality image generation, opening doors to a more accessible and competitive market for businesses seeking advanced T2I generative models.