
TL;DR:
- Language models are crucial in various AI applications, but their massive size poses challenges.
- Researchers are focused on enhancing efficiency by balancing model size and performance.
- Techniques like pruning and quantization offer promising avenues for compressing language models.
- A survey by Seoul National University researchers explores these optimization techniques comprehensively.
- Low-cost compression algorithms show surprising efficacy in reducing model size without compromising performance.
- These advancements pave the way for more accessible and sustainable language models, fostering inclusivity and driving progress in the AI market.
Main AI News:
In the realm of artificial intelligence, language models reign supreme, wielding the power of human language to fuel a multitude of applications. Their emergence has reshaped the landscape of text understanding and generation, ushering in advancements in translation, content creation, and conversational AI. However, their colossal size poses significant challenges, both in terms of computational requirements and environmental impact.
Efficiency is paramount in enhancing language models, striking a delicate balance between size and performance. While earlier models showcased remarkable capabilities, their immense operational demands have raised concerns regarding accessibility and sustainability. In response, researchers have embarked on a quest to develop novel techniques aimed at streamlining these models without compromising their prowess.
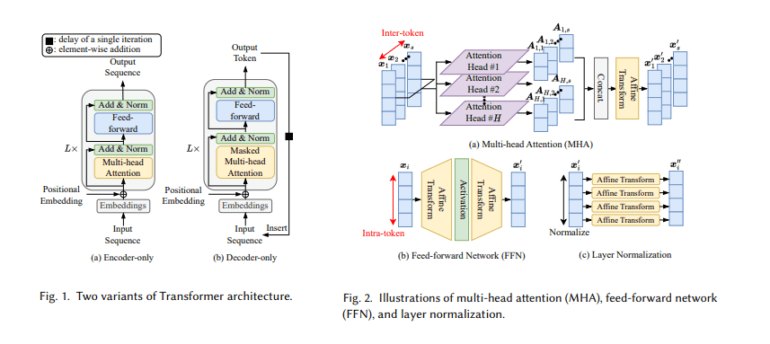
Key among these techniques are pruning and quantization, which offer avenues for substantial model reduction without sacrificing functionality. Pruning involves the surgical removal of redundant model components, while quantization simplifies numerical precision, effectively compressing the model’s footprint. These methods hold immense potential for creating more manageable and environmentally sustainable language models.
A recent survey conducted by Seoul National University researchers delves deep into the realm of optimization techniques, presenting a comprehensive analysis of high-cost precision methods alongside innovative low-cost compression algorithms. Particularly noteworthy are the latter approaches, which show promise in democratizing access to advanced AI capabilities. By significantly reducing model size and computational demands, these algorithms pave the way for a more inclusive AI landscape.
The study’s findings underscore the surprising effectiveness of low-cost compression algorithms in enhancing model efficiency. Despite being previously underexplored, these methods demonstrate remarkable potential in minimizing the footprint of large language models without sacrificing performance. Through meticulous analysis, the survey sheds light on the unique contributions of these techniques and outlines a roadmap for future research.
The implications of this research extend far beyond mere efficiency gains, heralding a future where advanced language processing capabilities are accessible to a broader user base. By making language models more accessible and sustainable, these optimization techniques lay the groundwork for further AI innovations, fostering inclusivity and driving progress across diverse applications.
Conclusion:
The survey analysis underscores the potential of low-cost compression algorithms in reshaping the landscape of AI by making advanced language processing capabilities more accessible. This trend towards efficiency innovations in language model compression signifies a shift towards inclusivity and sustainability in the AI market, opening doors for broader adoption and driving further advancements in various applications.