
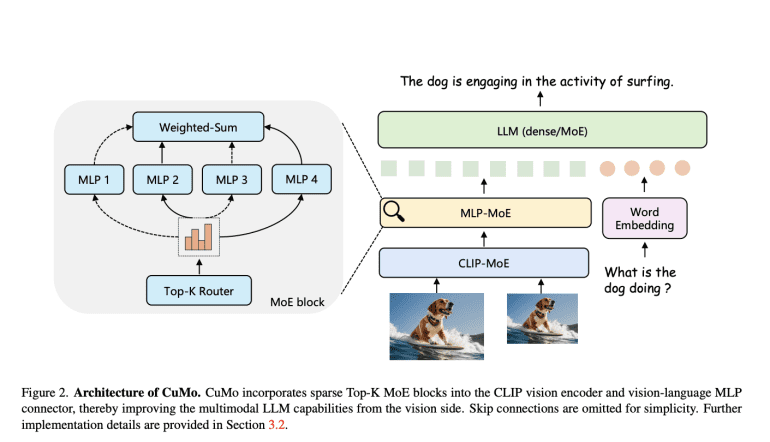
- CuMo integrates sparse MoE blocks into multimodal LLMs for enhanced efficiency.
- Co-upcycling optimizes MoE modules, leveraging pre-trained dense models.
- Three-stage training process aligns vision-language modalities and stabilizes performance.
- CuMo models outperform competitors across various benchmarks, even with smaller parameter sizes.
- Potential of CuMo to revolutionize AI systems for seamless text-image comprehension.
Main AI News:
The emergence of substantial language models (LLMs) like GPT-4 has ignited enthusiasm for augmenting them with multimodal capabilities to comprehend visual data alongside text. However, previous endeavors aimed at crafting robust multimodal LLMs encountered hurdles in scaling up effectively while preserving performance. To address these challenges, researchers drew inspiration from the mixture-of-experts (MoE) architecture, widely utilized for scaling LLMs by substituting dense layers with sparse expert modules.
In the MoE strategy, rather than directing inputs through a solitary large model, numerous smaller expert sub-models specialize in subsets of the data. A routing network determines which expert(s) should handle each input example, facilitating the expansion of total model capacity in a more parameter-efficient manner.
Enter CuMo, a groundbreaking approach where sparse MoE blocks are seamlessly integrated into the vision encoder and the vision-language connector of a multimodal LLM. This integration empowers distinct expert modules to concurrently process different aspects of visual and textual inputs, departing from the reliance on a monolithic model for comprehensive analysis.
A pivotal innovation lies in the concept of co-upcycling. Instead of commencing training of the sparse MoE modules from scratch, they are initialized from a pre-trained dense model before undergoing fine-tuning. Co-upcycling establishes a superior starting point for experts to specialize during training.
CuMo’s training regimen follows a meticulously designed three-stage process:
- Initial training solely focuses on the vision-language connector using image-text data such as LLaVA to align the modalities.
- All model parameters undergo joint pre-finetuning on caption data sourced from ALLaVA to optimize the full system’s performance.
- Finally, fine-tuning occurs with visual instruction data from datasets like VQAv2, GQA, and LLaVA-Wild, introducing co-upcycled sparse MoE blocks alongside auxiliary losses to balance expert load and stabilize training. This holistic approach, amalgamating MoE sparsity into multimodal models through co-upcycling and meticulous training, enables CuMo to scale up efficiently compared to mere model size augmentation.
Researchers evaluated CuMo models across various visual question-answering benchmarks like VQAv2 and GQA, as well as multimodal reasoning challenges including MMMU and MathVista. Figure 1 illustrates the performance of these models, trained exclusively on publicly accessible datasets, surpassing other state-of-the-art approaches within the same model size categories consistently. Even more impressively, compact 7B parameter CuMo models rivaled or outperformed significantly larger 13B alternatives across numerous challenging tasks.
These remarkable outcomes underscore the potential of sparse MoE architectures coupled with co-upcycling in crafting more adept yet efficient multimodal AI assistants. With the researchers openly sharing their work, CuMo could herald a new era of AI systems adept at seamlessly understanding and reasoning across text, images, and beyond.
Conclusion:
CuMo’s integration of sparse MoE blocks and co-upcycling techniques represents a significant breakthrough in advancing multimodal AI capabilities. With superior performance across benchmarks and efficient scaling even with smaller parameter sizes, CuMo sets a new standard for AI systems capable of seamlessly comprehending and reasoning across text and images. This development holds immense potential for reshaping the AI market, driving demand for more sophisticated and efficient multimodal AI assistants.