
- Google AI introduces Patchscopes to enhance understanding of Large Language Models (LLMs).
- Patchscopes utilizes LLMs to generate natural language explanations of their hidden representations.
- It aims to address limitations in transparency and comprehension of LLMs.
- Patchscopes offers insights into how LLMs process information and make predictions.
- The tool enhances transparency, control, and reliability of LLM behavior.
- It demonstrates effectiveness across various tasks, including next-token prediction and error correction.
Main AI News:
In the realm of artificial intelligence, the opacity of Large Language Models (LLMs) has long been a significant hurdle. Despite their remarkable capabilities, deciphering how these models arrive at their conclusions has remained a challenge. Google AI’s recent unveiling of Patchscopes marks a pivotal moment in this ongoing quest for transparency and comprehension.
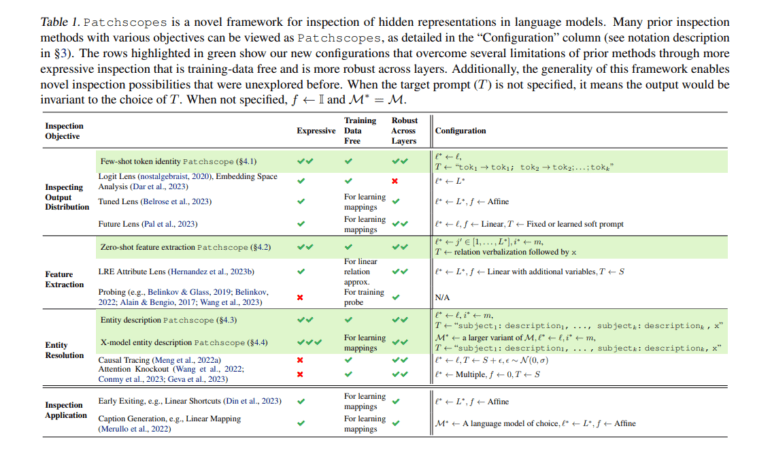
Patchscopes represents a paradigm shift in the realm of interpretability for LLMs. Unlike previous methods, which often relied on convoluted techniques, Patchscopes leverages the power of LLMs themselves to provide natural language explanations of their hidden representations. By harnessing the model’s own capabilities, Patchscopes transcends traditional limitations, offering insights into the inner workings of these complex systems.
This innovative approach holds immense promise for enhancing our understanding of LLMs. Through Patchscopes, researchers and developers gain unprecedented visibility into how these models process information and make predictions. By offering human-understandable explanations, Patchscopes not only increases transparency but also empowers users with greater control over LLM behavior.
At its core, Patchscopes works by injecting hidden LLM representations into target prompts and then analyzing the resulting explanations. Whether it’s unraveling the intricacies of co-reference resolution or shedding light on information processing and reasoning, Patchscopes provides invaluable insights at every layer of the model.
The efficacy of Patchscopes has been demonstrated across a spectrum of tasks, from next-token prediction to error correction. Its versatility and performance underscore its potential as a foundational tool for interpretable artificial intelligence.
In a landscape where trust and comprehension are paramount, Patchscopes represents a significant stride towards unlocking the black box of LLMs, paving the way for a future where artificial intelligence is not only powerful but also transparent and accountable.
Conclusion:
Patchscopes marks a significant advancement in the realm of artificial intelligence interpretability. Its introduction signifies a shift towards greater transparency and comprehension of Large Language Models. For businesses operating in AI-driven markets, Patchscopes offers a pathway to enhance trust, mitigate risks, and unlock new opportunities for innovation and development.