
- GraCoRe introduces a new benchmark for evaluating LLMs’ graph comprehension and reasoning abilities.
- It employs a three-tier hierarchical taxonomy across 11 datasets with over 5,000 graphs.
- Tasks include node classification, link prediction, maximum flow calculation, and more, testing LLMs on both pure and heterogeneous graphs.
- GPT-4o emerged as the top performer, showcasing strengths in semantic enrichment and structured data handling.
- The benchmark highlights areas for enhancing LLMs’ capabilities in complex graph-related tasks.
Main AI News:
In the realm of artificial intelligence, the ability of Large Language Models (LLMs) to comprehend and reason over graph-structured data stands as a critical frontier. This capability finds applications across diverse domains such as social network analysis, drug discovery, recommendation systems, and spatiotemporal predictions. The challenge lies in enhancing AI’s capacity to interpret complex relationships within varied types of graphs effectively.
However, evaluating LLMs in this context has been hindered by the absence of comprehensive benchmarks that can adequately assess their diverse capabilities. Existing benchmarks often focus narrowly on specific aspects of graph understanding, overlooking the broader spectrum of tasks that LLMs must handle. This limitation necessitates a more systematic approach to benchmarking—one that can offer a unified evaluation framework capable of testing LLMs across different graph structures and complexities.
To address these challenges, researchers from the Harbin Institute of Technology and Peng Cheng Laboratory have introduced GraCoRe—a groundbreaking benchmark designed to systematically evaluate LLMs’ graph comprehension and reasoning abilities. Built upon a three-tier hierarchical taxonomy, GraCoRe encompasses 11 datasets comprising over 5,000 graphs of varying complexities. This benchmark not only fills existing gaps but also sets a new standard by testing LLMs across pure and heterogeneous graph datasets.
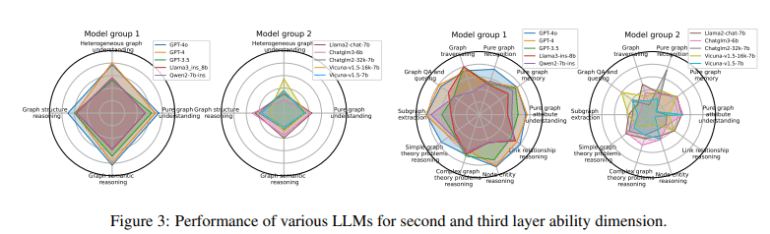
GraCoRe’s methodology involves structuring tasks across 19 distinct categories, ranging from node classification and link prediction to more intricate challenges like maximum flow calculation and shortest path determination. Each task is meticulously designed to assess specific capabilities, ensuring a comprehensive evaluation of LLMs’ proficiency in handling graph-structured data.
The initial evaluation of ten LLMs, including GPT-4o, GPT-4, and GPT-3.5, revealed insightful quantitative findings. GPT-4o emerged as the top performer, achieving exceptional scores across various tasks. For instance, in node number calculation, GPT-4o demonstrated robust performance with a score of 75.012, while excelling further in theoretical graph problems with a score of 99.268. These results underscore the importance of semantic enrichment and structured data handling in enhancing LLMs’ reasoning capabilities.
Moving forward, GraCoRe not only serves as a benchmark but also highlights areas for future research and development. It underscores the critical need to advance LLMs’ abilities in graph comprehension and reasoning, paving the way for more sophisticated AI models tailored to complex real-world applications.
Conclusion:
GraCoRe sets a new standard for assessing LLMs’ capabilities in graph comprehension and reasoning. This advancement is poised to drive innovation in AI, enhancing models’ ability to handle complex data structures across various industries, from healthcare to finance, paving the way for more sophisticated applications and solutions.