
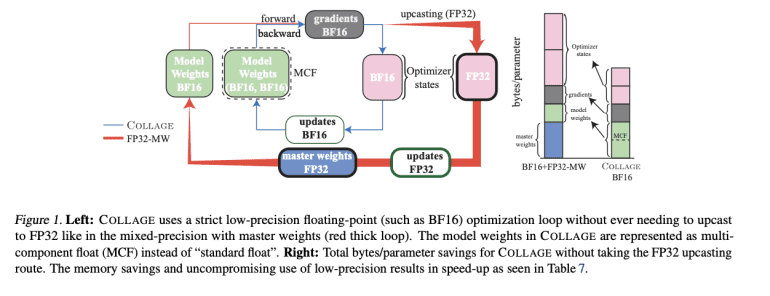
- COLLAGE addresses challenges in training large language models (LLMs) by using Multi-Component Float (MCF) representation.
- It optimizes efficiency and memory usage without requiring upcasting to higher precision formats.
- Integration with optimizers like AdamW leads to significant improvements in training throughput and memory savings.
- COLLAGE introduces the “effective descent quality” metric for evaluating precision strategies and understanding information loss.
- Performance-wise, COLLAGE boosts training throughput by up to 3.7x on a GPT-6.7B model while maintaining model accuracy comparable to FP32 master weights.
Main AI News:
Large language models (LLMs) have propelled the field of natural language processing forward, ushering in a new era of groundbreaking advancements across various applications such as machine translation, question-answering, and text generation. Yet, the training process for these models presents formidable challenges, characterized by high resource demands and protracted training durations owing to the intricate computations involved.
Traditionally, mitigating these challenges has involved exploring techniques like loss-scaling and mixed-precision strategies to alleviate memory consumption and bolster training efficiency for expansive models. However, these methods have encountered constraints stemming from numerical inaccuracies and constrained representation ranges, exerting adverse effects on overall model performance.
In response to these challenges, a collaborative effort between researchers at Cornell University and Amazon has yielded COLLAGE, a pioneering approach that harnesses the power of Multi-Component Float (MCF) representation to adeptly manage operations afflicted by numerical errors. This cutting-edge methodology not only optimizes efficiency and memory utilization during training but also circumvents the need for upcasting to higher precision formats, ensuring precise computations with a diminished memory footprint—a critical facet for LLM training.
COLLAGE’s integration as a plugin with optimizers such as AdamW has yielded substantial dividends, manifesting in noteworthy enhancements in training throughput and memory conservation when juxtaposed with conventional methodologies. Furthermore, a pivotal aspect of COLLAGE lies in its introduction of the “effective descent quality” metric, furnishing a nuanced evaluation of precision strategies and offering invaluable insights into information loss dynamics throughout the training continuum.
In terms of performance, COLLAGE has showcased remarkable speed-ups in training throughput, achieving a staggering 3.7x improvement on a GPT-6.7B model. Impressively, despite utilizing solely low-precision storage, COLLAGE upholds model accuracy at par with FP32 master weights, underscoring its prowess in striking an optimal balance between precision and efficiency in LLM training.
Conclusion:
The introduction of COLLAGE represents a significant advancement in the realm of large language model training. Its ability to enhance efficiency and memory utilization while maintaining model accuracy has profound implications for the market. With COLLAGE, businesses can expect faster training times, reduced resource requirements, and improved model performance, ultimately leading to more streamlined and effective natural language processing applications.