
- Large language models (LLMs) like GPT-4 and Llama are crucial for natural language processing applications.
- Vidur, developed by researchers from Georgia Tech and Microsoft Research India, is a simulation framework tailored for LLM inference.
- Vidur employs empirical data and predictive modeling to simulate LLM performance across various configurations.
- The framework features Vidur-Search, automating the exploration of cost-effective deployment settings.
- Vidur’s capabilities extend to evaluating multiple LLMs across different hardware setups and cluster configurations.
- Vidur-Bench, a benchmark suite, facilitates comprehensive performance evaluations using diverse workload patterns.
- Vidur has demonstrated significant cost reductions in LLM deployment, ensuring practical and effective performance optimizations.
Main AI News:
In the realm of natural language processing, large language models (LLMs) such as GPT-4 and Llama stand as indispensable tools, empowering a wide array of applications ranging from automated chatbots to sophisticated text analysis. Yet, their widespread deployment has long been plagued by two significant barriers: exorbitant costs and the intricate fine-tuning required to attain peak performance.
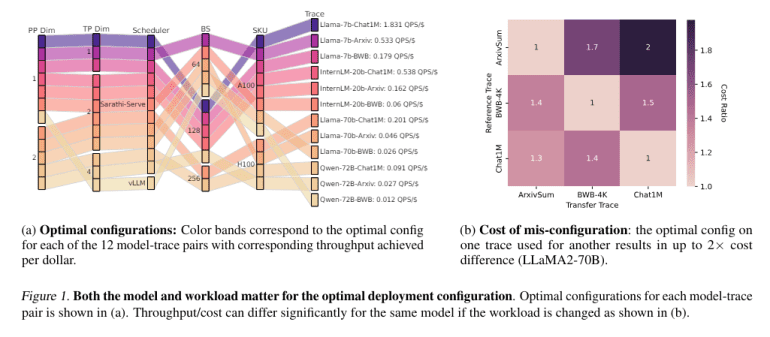
Historically, the deployment of LLMs necessitates a meticulous selection process among an array of system configurations, including but not limited to model parallelization, batching strategies, and scheduling policies. Traditionally, optimizing these configurations demanded extensive and financially burdensome experimentation. To illustrate, configuring the LLaMA2-70B model for optimal performance could entail over 42,000 GPU hours, translating to a staggering expense of approximately $218,000.
However, a groundbreaking solution has emerged from the collaborative efforts of researchers at the Georgia Institute of Technology and Microsoft Research India: Vidur, a cutting-edge simulation framework meticulously crafted for LLM inference. Leveraging a fusion of empirical data and predictive modeling, Vidur replicates LLM performance across diverse configurations, sidestepping the need for resource-intensive physical trials.
At the heart of Vidur lies its configuration search tool, Vidur-Search, a pioneering system automating the exploration of deployment configurations. This tool adeptly identifies the most cost-effective settings that align with predefined performance benchmarks. For instance, Vidur-Search swiftly determined an optimal setup for the LLaMA2-70B model on a CPU platform within a mere hour, a feat traditionally demanding copious GPU resources.
Vidur’s prowess extends beyond individual model assessments to encompass a comprehensive evaluation of various LLMs across diverse hardware setups and cluster configurations. Remarkably, it maintains a prediction accuracy rate of less than 9% error for inference latency, underscoring its reliability and robustness. Additionally, Vidur introduces Vidur-Bench, a sophisticated benchmark suite streamlining performance evaluations via diverse workload patterns and system configurations.
In practical terms, Vidur has ushered in a paradigm shift in LLM deployment, yielding substantial cost reductions. By leveraging Vidur-Search within simulation environments, organizations can drastically curtail potential expenses. What once would have incurred over $200,000 in real-world costs can now be simulated at a fraction of the expense. Crucially, this efficiency doesn’t compromise the accuracy or relevance of results, ensuring that performance optimizations remain both pragmatic and impactful.
Conclusion:
The emergence of Vidur signifies a transformative shift in the LLM deployment landscape, offering organizations a cost-effective means to optimize performance without compromising accuracy. This innovation has the potential to revolutionize the market by democratizing access to advanced natural language processing capabilities, thereby fostering innovation and driving efficiency across industries.