
TL;DR:
- Point-Bind revolutionizes 3D technology by integrating point clouds with various data sources.
- It enables 3D cross-modal retrieval, all-modal 3D generation, and 3D zero-shot classification.
- Point-LLM, a 3D language model, emerges as a game-changer for 3D question answering.
- Efficiency and resource savings are achieved through data and parameter-efficient techniques.
- The future focus is on expanding multi-modality with diverse 3D data for broader applications.
Main AI News:
In today’s rapidly evolving technological landscape, 3D vision stands as a beacon of innovation, drawing attention for its exponential growth and transformation. Its ascendancy can be predominantly attributed to the burgeoning demand for autonomous driving, sophisticated navigation systems, advanced 3D scene comprehension, and the ever-expanding field of robotics. To broaden its horizons, extensive efforts have been devoted to amalgamating 3D point clouds with data from diverse modalities, ushering in an era of enhanced 3D comprehension, text-to-3D generation, and 3D question answering.
Enter Point-Bind, a groundbreaking 3D multi-modality model meticulously engineered to seamlessly fuse point clouds with a myriad of data sources, including 2D images, language, audio, and video. Drawing inspiration from the proven principles of ImageBind, this paradigm-shifting model forges a unified embedding space that bridges the chasm between 3D data and multi-modalities. This pivotal breakthrough opens the door to a multitude of captivating applications, ranging from all-encompassing 3D generation to intricate 3D embedding calculations and a comprehensive grasp of the 3D open-world.
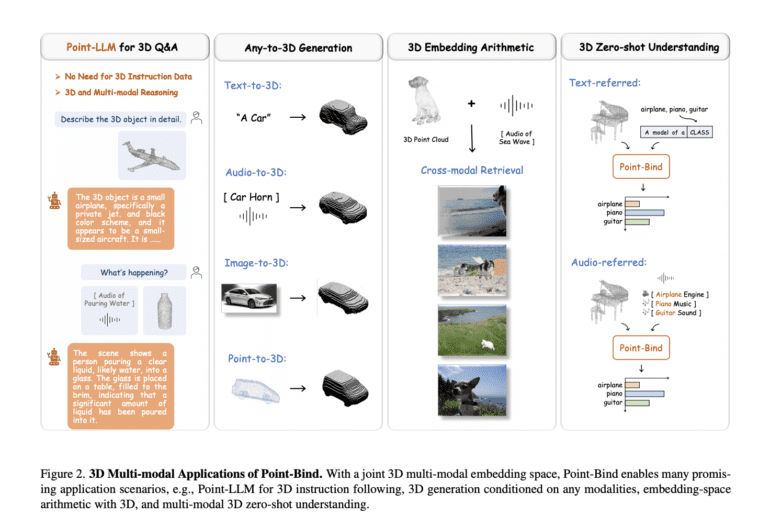
The schematic representation above delineates the seamless pipeline of Point-Bind. Researchers initiate the process by curating a treasure trove of 3D-image-audio-text data pairs for contrastive learning, expertly guided by ImageBind. Armed with a unified embedding space, Point-Bind becomes a versatile tool, offering capabilities like 3D cross-modal retrieval, dynamic all-modal 3D generation, intuitive 3D zero-shot comprehension, and the evolution of a groundbreaking 3D language model known as Point-LLM.
The key contributions of Point-Bind are as follows:
- Synthesizing 3D with ImageBind: In a shared embedding space, Point-Bind adeptly aligns 3D point clouds with a plethora of multi-modalities, under the sagacious guidance of ImageBind. This includes harmonizing 3D with 2D images, video, language, audio, and more.
- Universal 3D Generation: Drawing inspiration from existing text-to-3D generative models, Point-Bind empowers 3D shape synthesis, conditioned by any modality – be it text, image, audio, or point-to-mesh generation.
- 3D Embedding-space Calculations: Observations reveal that the 3D features harnessed by Point-Bind can be seamlessly integrated with other modalities, injecting their semantic essence and thereby enabling holistic cross-modal retrieval.
- Mastering 3D Zero-shot Comprehension: Point-Bind stands tall as a paragon of 3D zero-shot classification prowess. Moreover, it extends its capabilities to encompass audio-guided 3D open-world comprehension, transcending the boundaries of text references.
Researchers harness the power of Point-Bind to usher in a new era of 3D large language models (LLMs), aptly named Point-LLM. Through the delicate finetuning of LLaMA, they accomplish the feat of 3D question answering and multi-modal reasoning, as illuminated in the diagram above.
The salient features of Point-LLM are as follows:
- Point-LLM for 3D Question Answering: Point-Bind paves the way for Point-LLM, the pioneering 3D LLM that delivers responses with 3D point cloud context, catering to both English and Chinese languages.
- Efficiency in Data and Parameters: Achieving unprecedented efficiency, Point-LLM relies solely on publicly available vision-language data for tuning, devoid of any 3D instruction data. It also adopts parameter-efficient finetuning techniques, preserving valuable resources.
- 3D and Multi-modal Reasoning: Leveraging the joint embedding space, Point-LLM empowers the generation of insightful responses by skillfully blending 3D and multi-modal inputs, such as point clouds with images or audio.
The future trajectory of this groundbreaking research will concentrate on harmonizing multi-modality with an even wider array of 3D data, spanning indoor and outdoor scenes, thereby expanding the horizons of application scenarios.
Conclusion:
Point-Bind’s innovative integration of 3D data with multiple modalities opens doors to a wide range of applications, from enhanced 3D generation to efficient question answering. Its potential for data and parameter efficiency positions it as a valuable asset in the evolving tech market, with broader applications on the horizon.