
- PyTorch introduces TK-GEMM, an optimized Triton FP8 GEMM kernel, targeting enhanced inference for large language models (LLMs) like Llama3.
- TK-GEMM addresses inefficiencies in PyTorch execution by leveraging Triton Kernels to consolidate multiple operations into single GPU kernel launches.
- The kernel utilizes SplitK parallelization to decompose workloads, resulting in significant performance improvements for Llama3-70B models.
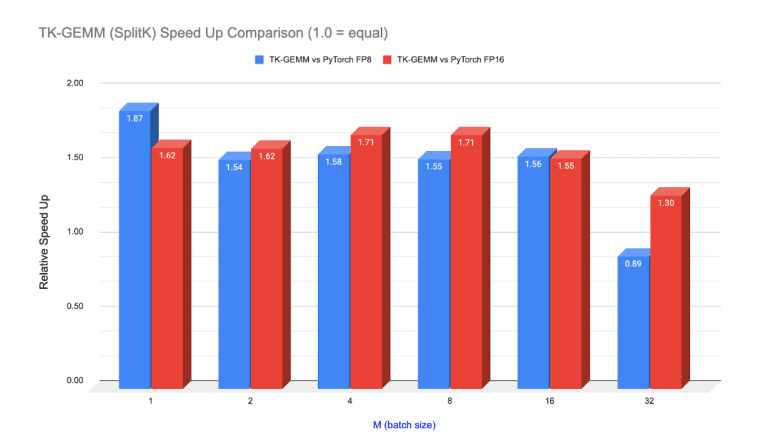
- Experimental results demonstrate up to 1.94 times speedup over base Triton matmul, 1.87 times over cuBLAS FP8, and 1.71 times over cuBLAS FP16 for Llama3-70B inference.
- Integration of CUDA graphs further enhances efficiency by reducing kernel launch latencies, leading to substantial performance gains in production settings.
Main AI News:
In response to the pressing need for accelerated FP8 inference in large language models (LLMs) such as Llama3, PyTorch has introduced TK-GEMM, a refined Triton FP8 GEMM kernel. This innovation aims to tackle the inefficiencies inherent in standard PyTorch execution when handling LLM operations, particularly the overhead associated with launching multiple kernels on the GPU.
The conventional PyTorch approach often grapples with the challenge of managing numerous kernel launches, leading to suboptimal inference performance. However, PyTorch’s integration of Triton Kernels offers a promising solution. These kernels, tailored for specific hardware configurations like Nvidia GPUs, optimize performance by consolidating multiple operations into a single kernel launch. Developers can seamlessly incorporate Triton kernels into PyTorch models using the torch.compile() function, thereby reducing overhead and enhancing performance.
Notably, Triton kernels leverage specialized FP8 Tensor Cores available on Nvidia GPUs, contributing to superior computational efficiency compared to conventional FP16 cores used in PyTorch’s cuBLAS library.
TK-GEMM leverages SplitK parallelization to further enhance performance for Llama3-70B models by decomposing workloads along the k dimension and deploying additional thread blocks to compute partial output sums. This refined approach enables finer-grained work decomposition, resulting in substantial speedups over the base Triton GEMM implementation.
Experimental findings demonstrate remarkable improvements, including a 1.94 times speedup over the base Triton matmul implementation, a 1.87 times speedup over cuBLAS FP8, and a 1.71 times speedup over cuBLAS FP16 for Llama3-70B inference problem sizes. Moreover, the integration of CUDA graphs introduces additional efficiencies by reducing kernel launch latencies. By employing graphs instead of launching multiple kernels, developers can minimize CPU overhead, leading to significant performance gains in real-world scenarios.
Conclusion:
PyTorch’s introduction of TK-GEMM marks a significant advancement in streamlining inference processes for large language models. With notable speed improvements and enhanced efficiency achieved through Triton Kernels and SplitK parallelization, this innovation promises to revolutionize the market by enabling faster, more efficient model inference, particularly for applications requiring high computational throughput. Industries reliant on LLMs stand to benefit greatly from these advancements, with potential implications for fields such as natural language processing, machine translation, and conversational AI.