
- Researchers at UC San Diego propose DrS, a novel machine learning approach for dense reward learning in multi-stage tasks.
- DrS integrates sparse rewards as a supervision signal, facilitating the learning of reusable rewards.
- The model consists of two phases: Reward Learning and Reward Reuse, ensuring effective guidance through task progression.
- Evaluation on physical manipulation tasks demonstrates the superiority of learned rewards over baseline rewards, sometimes rivaling human-engineered rewards.
- DrS offers significant potential for enhancing the adaptability and performance of reinforcement learning algorithms across diverse task domains.
Main AI News:
Recent advancements in reinforcement learning (RL) have emphasized the significance of dense reward functions. However, creating these functions can be challenging, often requiring specialized expertise and extensive trial and error. Meanwhile, sparse rewards, such as simple task completion signals, are more accessible but present their own set of obstacles, particularly for RL algorithms in terms of exploration. This raises a critical question: Can dense reward functions be acquired through a data-driven approach to tackle these challenges effectively?
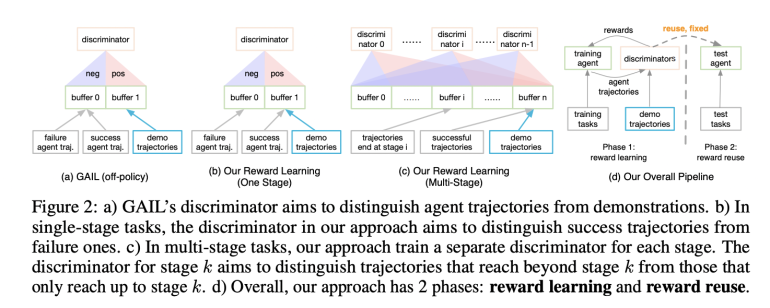
While existing research has explored reward learning, there’s been a notable oversight regarding the reusability of rewards for new tasks. In the realm of inverse RL, methods like adversarial imitation learning (AIL) have gained prominence. Drawing inspiration from Generative Adversarial Networks (GANs), AIL employs a policy network and a discriminator to generate and discern trajectories, respectively. However, AIL’s rewards lack reusability across tasks, thereby limiting its capacity to adapt to novel tasks efficiently.
In response, researchers from UC San Diego introduce Dense reward learning from Stages (DrS), a pioneering approach aimed at learning reusable rewards. DrS integrates sparse rewards as a supervisory signal for training a discriminator to classify success and failure trajectories, rather than relying solely on the original signal. This methodology assigns higher rewards to transitions in success trajectories and lower rewards to transitions within failure trajectories, ensuring consistency during training and enabling the rewards to be reused once training is completed. Expert demonstrations can supplement success trajectories, but they’re not obligatory, as sparse rewards suffice, typically inherent in task definitions.
The DrS model comprises two phases: Reward Learning and Reward Reuse. In the Reward Learning phase, a classifier is trained to differentiate between successful and unsuccessful trajectories using sparse rewards, serving as a dense reward generator. The subsequent Reward Reuse phase applies the learned dense reward to train new RL agents across various tasks. Stage-specific discriminators are trained to furnish dense rewards for multi-stage functions, guiding task progression effectively.
To assess the efficacy of the proposed model, it was evaluated across three intricate physical manipulation tasks: Pick-and-Place, Turn Faucet, and Open Cabinet Door, each involving diverse objects. The evaluation primarily focused on the reusability of learned rewards, employing non-overlapping training and test sets for each task category. During the Reward Learning phase, rewards were acquired by training agents to manipulate training objects, and these rewards were subsequently repurposed to train agents on test objects in the Reward Reuse phase. The evaluation employed the Soft Actor-Critic (SAC) algorithm. Results showcased that the learned rewards consistently outperformed baseline rewards across all task categories, occasionally rivaling human-engineered rewards. While semi-sparse rewards exhibited limited success, alternative reward learning methods failed to achieve comparable results.
Conclusion:
The introduction of DrS represents a significant advancement in machine learning, particularly for reinforcement learning applications in multi-stage tasks. By enabling the learning of reusable rewards through a data-driven approach, DrS has the potential to revolutionize various industries reliant on autonomous systems, including robotics, gaming, and autonomous vehicles. Its ability to outperform baseline rewards underscores its efficacy in addressing challenges associated with reward design, thereby paving the way for more efficient and adaptable AI systems in the market.