
TL;DR:
- RTMO is a groundbreaking framework developed by top institutions for real-time multi-person pose estimation.
- It overcomes the trade-off between accuracy and speed, outperforming existing methods by integrating coordinate classification and dense prediction models.
- This one-stage framework achieves higher accuracy while operating up to nine times faster with the same infrastructure.
- RTMO-l, the largest model, reaches 74.8% AP on COCO val2017 and runs at 141 frames per second on a single V100 GPU.
- Across different scenarios, RTMO outperforms lightweight one-stage methods in both performance and speed.
- With additional training data, RTMO-l achieves a state-of-the-art 81.7 Average Precision.
- The framework generates precise heatmaps for context-aware predictions.
Main AI News:
The realm of pose estimation, responsible for pinpointing the spatial orientation and location of objects, remains in a state of constant evolution. Researchers from three esteemed institutions—Tsinghua Shenzhen International Graduate School, Shanghai AI Laboratory, and Nanyang Technological University—have ushered in a new era with the introduction of the groundbreaking RTMO framework. This innovative system holds the potential to elevate the precision and efficiency of pose estimation, promising far-reaching applications in fields such as robotics, augmented reality, and virtual reality.
RTMO represents a significant leap forward in the realm of pose estimation. Unlike its predecessors, which often grappled with the delicate balance between accuracy and real-time performance, this one-stage framework redefines the status quo. By seamlessly integrating coordinate classification and dense prediction models, RTMO catapults itself ahead of other one-stage pose estimators. It achieves accuracy comparable to top-down approaches while delivering unmatched speed.
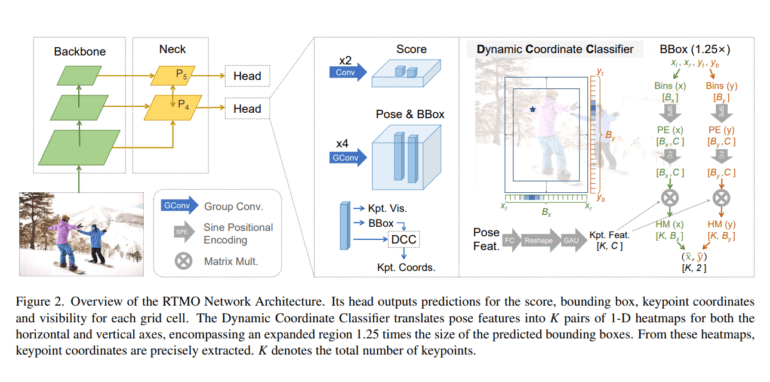
The pursuit of real-time multi-person pose estimation presents a formidable challenge within the realm of computer vision. Existing methodologies grapple with the arduous task of harmonizing speed and precision. RTMO, however, stands as a beacon of hope, weaving together a dynamic coordinate classifier with a tailored loss function for heatmap learning. Through the deployment of Dynamic Bin Encoding for creating bin-specific representations and Gaussian label smoothing with cross-entropy loss for classification tasks, RTMO surmounts the limitations of its predecessors.
At its core, RTMO boasts a YOLO-like architecture with CSPDarknet as its backbone and a Hybrid Encoder. Dual convolution blocks, operating at various spatial levels, proficiently generate scores and pose features. The framework tackles the challenges stemming from the incongruities between coordinate classification and dense prediction models. It does so by implementing a dynamic coordinate classifier and a customized loss function, ensuring the synergy between these critical components.
RTMO, the one-stage pose estimation pioneer, shines in the realm of multi-person pose estimation, setting new standards for precision and real-time performance. When compared to the most cutting-edge one-stage pose estimators, RTMO emerges as the victor, boasting a 1.1% higher Average Precision on COCO while clocking in at a remarkable nine times faster, all with the same underlying infrastructure. In its grandest form, RTMO-l notches an impressive 74.8% AP on COCO val2017 and attains a formidable 141 frames per second on a single V100 GPU. Across diverse scenarios, the RTMO series consistently outperforms its lightweight one-stage counterparts, firmly establishing its dominance in both efficiency and accuracy. With additional training data, RTMO-l even achieves a state-of-the-art 81.7 Average Precision, setting the gold standard for performance. The framework’s prowess in generating spatially accurate heatmaps bolsters its ability to provide resilient and context-aware predictions for each key point.
Conclusion:
RTMO’s advent marks a watershed moment in real-time multi-person pose estimation. Its fusion of precision and speed opens up new horizons in various industries, promising to reshape the landscape of robotics, augmented reality, and virtual reality. With the RTMO framework at the forefront, we can anticipate a future defined by unprecedented accuracy and efficiency in pose estimation.