
TL;DR:
- SAM-PT is an innovative AI method that extends the capabilities of SAM for video segmentation by incorporating point tracking.
- Existing approaches in video segmentation struggle with untried data and zero-shot scenarios.
- SAM, a powerful image segmentation model, has remarkable zero-shot generalization skills.
- SAM-PT combines sparse point tracking with SAM, enabling it to segment and track objects in dynamic videos.
- Researchers from ETH Zurich, HKUST, and EPFL introduce SAM-PT as the first method to segment videos using sparse point tracking and SAM.
- SAM-PT offers superior generalization to unseen objects and achieves impressive results on the UVO benchmark.
- SAM-PT accelerates progress in zero-shot video segmentation tasks without the need for video segmentation data during training.
Main AI News:
In today’s rapidly evolving technological landscape, video segmentation plays a crucial role in numerous applications, ranging from robotics and autonomous driving to video editing. While deep neural networks have made significant strides in recent years, there still exist challenges when it comes to untried data, particularly in zero-shot scenarios. Existing approaches often falter when dealing with video domains they haven’t been trained on or encompassing object categories outside the training distribution. This is where SAM-PT (Segment Anything Meets Point Tracking) comes into play, a groundbreaking AI method that extends the capabilities of the Segment Anything Model (SAM) to track and segment anything in dynamic videos.
One potential solution to the aforementioned challenges lies in leveraging successful models from the image segmentation domain for video segmentation tasks. SAM is a promising concept that embodies this approach. With a massive training set consisting of 11 million pictures and over 1 billion masks, SAM was trained on the SA-1B dataset, establishing itself as a robust foundation model for image segmentation. What truly sets SAM apart is its remarkable zero-shot generalization skills, made possible by its extensive training. This model has demonstrated consistent and reliable performance across diverse scenarios, using zero-shot transfer protocols, and possesses the ability to generate high-quality masks from a single foreground point.
While SAM excels in image segmentation, it initially lacked natural suitability for video segmentation problems. However, recent advancements have led to the development of SAM-PT, which integrates video segmentation capabilities into SAM. For instance, TAM combines SAM with the cutting-edge memory-based mask tracker XMem, while SAM-Track combines DeAOT with SAM. Although these techniques successfully restore SAM’s performance on in-distribution data, they fall short when faced with more challenging zero-shot conditions. To overcome this limitation, researchers have explored visual prompting techniques that do not rely on SAM, such as SegGPT. However, these techniques still require mask annotation for the initial video frame.
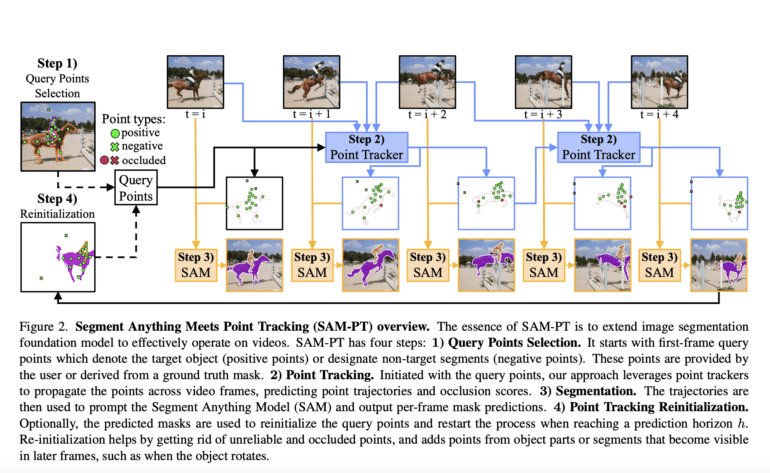
Addressing this critical issue, researchers from ETH Zurich, HKUST, and EPFL have introduced SAM-PT, an innovative approach that combines sparse point tracking and SAM to tackle video segmentation challenges. Rather than relying on mask propagation or object-centric dense feature matching, SAM-PT leverages a point-driven method that harnesses the intricate local structural data encoded in movies to track points. This groundbreaking approach minimizes the need for extensive annotations and offers superior generalization to unseen objects. Remarkably, SAM-PT’s capabilities have been validated through its outstanding performance on the open-world UVO benchmark.
By leveraging the adaptability of modern point trackers like PIPS, SAM-PT prompts SAM with sparse point trajectories predicted using these tools. Notably, researchers have discovered that initializing locations to track using K-Medoids cluster centers from a mask label serves as the most effective strategy for motivating SAM. With this approach, SAM-PT effectively expands the capabilities of SAM to encompass video segmentation, while retaining its intrinsic flexibility.
To distinguish between the backdrop and target items, SAM-PT utilizes both positive and negative points for tracking. The researchers propose distinct mask decoding processes that utilize these points to enhance the output masks further. Additionally, they have developed a point re-initialization technique that improves tracking precision over time. This technique discards unreliable or obscured points while incorporating points from sections or segments of the object that become visible in successive frames, such as during object rotation.
Crucially, the test findings demonstrate that SAM-PT performs on par with, if not better than, existing zero-shot approaches across several video segmentation benchmarks. Notably, SAM-PT achieves these remarkable results without requiring any video segmentation data during training. In zero-shot settings, SAM-PT has the potential to significantly accelerate progress in video segmentation tasks. To experience SAM-PT’s capabilities firsthand, the researchers have made multiple interactive video demos available on their website.
Conclusion:
The introduction of SAM-PT and its integration of point tracking into SAM represents a significant advancement in the field of video segmentation. This breakthrough method addresses the challenges posed by untried data and zero-shot scenarios, offering superior generalization and high-quality segmentation results. SAM-PT has the potential to revolutionize the market by enabling businesses in robotics, autonomous driving, and video editing to achieve more accurate and efficient video segmentation. With its remarkable performance on the UVO benchmark and the ability to accelerate progress in zero-shot video segmentation tasks, SAM-PT establishes itself as a valuable tool in the industry, empowering companies to unlock new possibilities in video processing and AI-driven applications.