
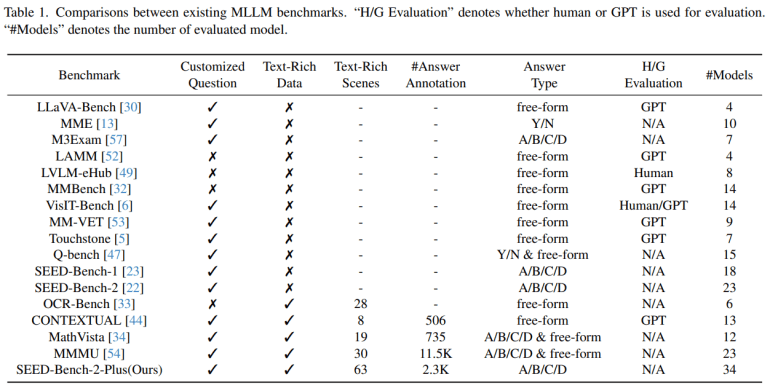
- SEED-Bench-2-Plus is a new benchmark tailored for evaluating Multimodal Large Language Models (MLLMs) in text-heavy scenarios.
- Developed by experts from Tencent AI Lab and other institutions, it features 2.3K meticulously crafted multiple-choice questions covering charts, maps, and webs.
- The benchmark aims to address the shortcomings of existing evaluation methods by providing a comprehensive assessment framework for MLLMs’ understanding of text-rich visual content.
- Utilizing a variety of data types, SEED-Bench-2-Plus employs an answer-ranking strategy to evaluate MLLMs’ performance without relying solely on model instruction-following capabilities.
- Evaluation results reveal that while some MLLMs perform well, many struggle with text-rich data, indicating the need for further research to enhance their proficiency in such scenarios.
Main AI News:
Assessing Multimodal Large Language Models (MLLMs) in text-rich environments stands as a critical task, considering their expanding range of applications. However, existing benchmarks primarily evaluate general visual understanding, sidelining the intricate hurdles of text-enriched contexts. While models like GPT-4V, Gemini-Pro-Vision, and Claude-3-Opus exhibit remarkable prowess, their evaluation often falls short in text-rich scenarios. Deciphering text embedded in images demands interpreting both textual and visual signals, a hurdle yet to be exhaustively tackled.
Crafted by experts from Tencent AI Lab, ARC Lab, Tencent PCG, and The Chinese University of Hong Kong, Shenzhen, SEED-Bench-2-Plus emerges as a tailored benchmark meticulously designed to gauge MLLMs’ grasp of text-heavy visual content. Featuring a curated collection of 2.3K finely-crafted multiple-choice queries spanning three main categories: charts, maps, and webs, it encapsulates a diverse array of real-world contexts. Rigorously vetted by human annotators for precision, this benchmark evaluates the performance of 34 prominent MLLMs, including GPT-4V, Gemini-Pro-Vision, and Claude-3-Opus.
The landscape of MLLMs witnesses a proliferation aimed at enriching comprehension across text and images. While some endeavors integrate video inputs, others concentrate on generating visual content from textual prompts. Nevertheless, the efficacy of these models in text-dense environments remains a subject ripe for exploration. SEED-Bench-2-Plus steps into this void by furnishing a comprehensive benchmark to scrutinize MLLMs’ efficacy in deciphering text-laden visual data. Unlike its predecessors, this benchmark spans a wide spectrum of real-world scenarios, sidestepping biases introduced by human annotators and furnishing a crucial instrument for impartial evaluation and progression in this sphere.
SEED-Bench-2-Plus unfolds a comprehensive assessment framework comprising 2K multiple-choice questions across the three principal categories: charts, maps, and webs. Each category encompasses a plethora of data types, totaling 63 in aggregate. The dataset undergoes meticulous curation, comprising charts, maps, and website snapshots teeming with textual cues. Leveraging the capabilities of GPT-4V, questions are generated and meticulously refined by human annotators. Evaluation adopts an answer-ranking paradigm, appraising MLLMs’ efficacy based on the likelihood of formulating the correct response for each option. Unlike conventional methodologies, this approach mitigates reliance on model instruction adherence and neutralizes the influence of multiple-choice option order on performance metrics.
The evaluation encompasses a diverse array of 31 open-source MLLMs and three proprietary ones across various categories of SEED-Bench-2-Plus. GPT-4V emerges as a frontrunner, exhibiting superior performance across a myriad of evaluation modalities. However, the majority of MLLMs grapple with text-intensive datasets, registering an average accuracy rate of under 40%, underscoring the intricacies inherent in comprehending such data. Maps present formidable challenges owing to their multi-layered nature, while performance nuances manifest across disparate data types within each category. These findings accentuate the imperative for continued research endeavors aimed at augmenting MLLMs’ efficacy in text-rich scenarios, thereby ensuring adaptability across a diverse array of data types.
Conclusion:
The introduction of SEED-Bench-2-Plus signifies a significant advancement in the evaluation of Multimodal Large Language Models (MLLMs) in text-rich environments. This tailored benchmark provides a standardized framework for assessing MLLMs’ comprehension of text-heavy visual content, addressing the limitations of existing evaluation methods. As MLLMs continue to play a crucial role in various industries, the insights garnered from SEED-Bench-2-Plus will inform the development of more effective models, driving innovation and progress in the market for text-based AI solutions.