
- CE models redefine similarity evaluation, outperforming traditional methods.
- Sparse-matrix factorization offers efficient computation for CE score approximation.
- Novel method optimizes computation of latent query and item representations.
- Significantly reduces computational overhead compared to existing techniques.
- Rigorous evaluation demonstrates efficacy across various tasks and datasets.
- Proposed k-NN search method enhances recall and offers notable speedups.
- Represents a significant advancement in improving test-time k-NN search efficiency.
Main AI News:
Recent advancements in cross-encoder (CE) models have revolutionized similarity evaluation in query-item pairs, surpassing traditional methods like dot-product with embedding-based models in determining query-item relevance. However, existing approaches, including those employing dual-encoders (DE) or CUR matrix factorization, struggle with limitations such as poor recall in new domains and decoupling of test-time retrieval from CE. Consequently, these methods prove inadequate for specific k-NN search scenarios.
In response, researchers have delved into sparse-matrix factorization methods as an alternative. Matrix factorization, long employed for dense matrices, is now being adapted for sparse matrices, promising more efficient computation. By capitalizing on the assumption of low-rank underlying matrices, this approach effectively recovers missing entries using only a small fraction of available data. Furthermore, leveraging feature descriptions for matrix rows and columns enhances the complexity of sample recovery, particularly for matrices with more rows than columns.
A groundbreaking approach, introduced by researchers from the University of Massachusetts Amherst and Google DeepMind, optimizes sparse-matrix factorization for computing latent query and item representations to approximate CE scores. This method not only improves the quality of approximation compared to CUR-based techniques but also significantly reduces the computational overhead by requiring fewer CE similarity calls. By factorizing a sparse matrix containing query-item CE scores, the method derives item embeddings, initializing the embedding space through DE models.
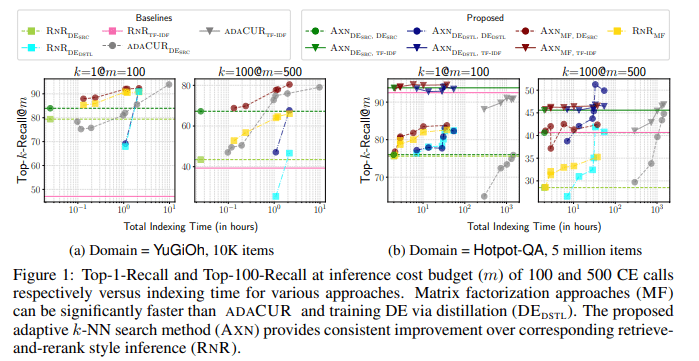
Evaluation of these methods and corresponding baselines involves rigorous testing across various tasks, including k-nearest neighbor retrieval for CE models and related downstream tasks like zero-shot entity linking and information retrieval. Experiments conducted on ZESHEL and BEIR datasets, utilizing separate CE models trained on labeled data for each, showcase the efficacy of the proposed approach. Notably, the method demonstrates substantial improvements in k-NN recall, especially for higher values of k, compared to conventional retrieve and rerank methods.
Furthermore, a novel k-NN search method is proposed, leveraging dense item embeddings from baseline dual-encoder models. This approach not only enhances recall significantly but also offers notable speedups compared to CUR-based methods and distillation-based training approaches for DE. By aligning item embeddings with cross-encoder outputs, this method represents a significant advancement in improving test-time k-NN search efficiency over existing baseline techniques.
Conclusion:
The introduction of sparse-matrix factorization techniques for CE score approximation represents a significant advancement in the market, promising enhanced efficiency and accuracy in similarity evaluation tasks. With the potential to reduce computational overhead and improve retrieval performance, this innovation is poised to reshape approaches to information retrieval and similarity assessment, offering businesses a competitive edge in handling large-scale data processing tasks.