
TL;DR:
- Videos in various forms flood the global content landscape daily, necessitating advanced methods for cognitive machines to analyze them effectively.
- Extended-duration videos present unique challenges, requiring sophisticated analysis techniques to extract information and maintain narrative coherence.
- Recent advancements in large pre-trained and video-language models offer promise but have limitations in handling complex real-world videos.
- MM-VID, powered by GPT-4V, integrates specialized tools for video understanding, including scene detection, ASR, and narrative generation.
- MM-VID’s ability to process, dissect, and analyze videos at scale opens up new possibilities in the realm of AI video comprehension.
Main AI News:
In today’s global landscape, an abundance of videos is created daily, spanning user-generated live streams, video-game broadcasts, short clips, cinematic masterpieces, sports events, and advertising campaigns. Videos serve as a versatile medium, conveying information through a blend of text, visuals, and audio. To equip cognitive machines with the prowess to dissect uncurated real-world videos, it is imperative to develop methodologies that can harness the diverse modalities within them, transcending the confines of meticulously curated datasets.
However, the richness of this representation ushers in a slew of challenges, especially when dealing with extended-duration videos. Grasping the intricacies of lengthy videos, particularly those surpassing the hour mark, necessitates the deployment of sophisticated techniques for analyzing images and audio sequences across numerous segments. This complexity amplifies when the objective is to extract information from heterogeneous sources, distinguish between different speakers, identify characters, and maintain narrative coherence. Furthermore, the task of answering questions based on video evidence calls for a profound understanding of the content, context, and subtitles.
In the realm of live streaming and gaming videos, additional hurdles surface as real-time processing of dynamic environments requires semantic acumen and the ability to engage in long-term strategic planning.
Recent times have witnessed significant strides in the domain of large pre-trained and video-language models, showcasing their adeptness in reasoning through video content. Nevertheless, these models are predominantly trained on succinct clips, often lasting no more than 10 seconds or predefined action categories. Consequently, they may grapple with limitations when it comes to providing a nuanced comprehension of intricate real-world videos.
Comprehending real-world videos entails the identification of individuals within a scene and the discernment of their actions. Furthermore, it necessitates the precise specification of when and how these actions unfold. It also demands the ability to discern subtle nuances and visual cues across diverse scenes. The primary objective of this endeavor is to confront these challenges head-on and investigate methodologies that can be directly applied to comprehending real-world videos. The proposed approach involves breaking down extended video content into cohesive narratives and subsequently harnessing these narratives for video analysis.
Recent advancements in Large Multimodal Models (LMMs), exemplified by GPT-4V(ision), have heralded a new era in the processing of both visual and textual inputs for multimodal understanding. This has ignited interest in extending the reach of LMMs to the realm of videos. The study outlined in this article introduces MM-VID, a cutting-edge system that seamlessly integrates specialized tools with GPT-4V for video comprehension.
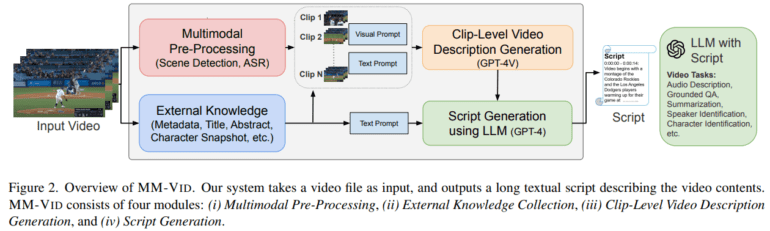
Upon receiving an input video, MM-VID embarks on a multimodal pre-processing journey, which includes scene detection and automatic speech recognition (ASR), to glean vital information from the video. Subsequently, the input video is dissected into multiple clips based on the scene detection algorithm. GPT-4V then takes the reins, employing clip-level video frames as input to craft intricate descriptions for each video segment. Finally, GPT-4V weaves these descriptions into a coherent script for the entire video, all while considering clip-level video descriptions, ASR transcripts, and available video metadata. The generated script empowers MM-VID to execute a diverse range of video-related tasks with finesse, opening new frontiers in advanced AI video understanding.
Conclusion:
The integration of MM-VID with GPT-4V marks a significant advancement in the understanding of AI video. This technology has the potential to revolutionize various industries, including entertainment, e-learning, surveillance, and more, by enabling machines to comprehend and analyze video content with unprecedented depth and accuracy. This could lead to enhanced user experiences, better content recommendations, and improved decision-making capabilities across multiple sectors, making it a game-changer in the market.