
- Amazon AWS AI Labs introduces SpeechVerse, a groundbreaking multi-task framework for audio intelligence.
- SpeechVerse excels in 11 diverse tasks, leveraging scalable multimodal instruction fine-tuning.
- Its adaptive instruction-following capability and innovative decoding strategies enhance generalization by up to 21%.
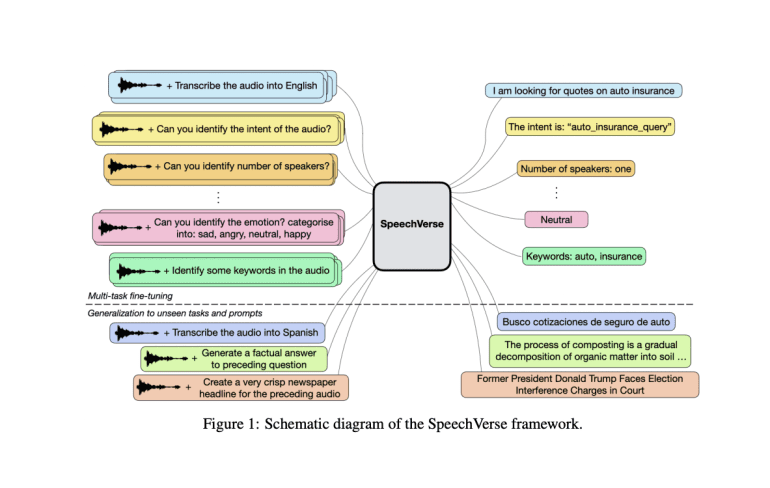
- The multimodal architecture includes a pre-trained audio encoder, 1-D convolution module, and pre-trained LLM.
- Three variants of SpeechVerse framework cater to task-specific optimization and holistic comprehension.
- SpeechVerse outperforms conventional baselines on 9 out of 11 tasks, showcasing robust performance across datasets.
- Future enhancements aim at decoupling task specification from model architecture, enabling seamless adaptation to new tasks.
Main AI News:
In the realm of artificial intelligence, the prowess of large language models (LLMs) is undeniable. These models have continuously proven their mettle across diverse natural language tasks, exhibiting a remarkable capacity for generalization. However, a glaring gap persists: LLMs fall short in comprehending non-textual modalities, particularly audio.
Enter SpeechVerse: A Groundbreaking Leap in Audio Intelligence
In a groundbreaking endeavor, the research team at Amazon AWS AI Labs introduces SpeechVerse, a pioneering multi-task framework poised to redefine the landscape of audio intelligence. Their latest paper, “SpeechVerse: A Large-scale Generalizable Audio Language Model,” unveils the potential of SpeechVerse to transcend the limitations of traditional LLMs.
Key Innovations Driving SpeechVerse’s Dominance
- Scalable Multimodal Instruction Fine-tuning: SpeechVerse heralds a new era with its innovative approach to audio-language integration. This novel framework, underpinned by LLM technology, showcases unparalleled performance across 11 distinct tasks. Through meticulous benchmarking on public datasets encompassing Automatic Speech Recognition (ASR), spoken language understanding, and paralinguistic speech tasks, SpeechVerse emerges as a frontrunner in audio intelligence.
- Adaptive Instruction-Following Capability: Leveraging the robust language comprehension abilities ingrained in its LLM foundation, SpeechVerse exhibits a remarkable capacity to adapt to diverse tasks, even those not explicitly included during multimodal fine-tuning. This versatility underscores SpeechVerse’s adaptability in navigating uncharted territories within the audio domain.
- Strategies for Enhanced Generalization: The research team’s exploration of innovative prompting and decoding strategies yields tangible dividends in SpeechVerse’s generalization prowess. From constrained to joint decoding methodologies, these strategic interventions amplify the model’s ability to excel in previously unseen tasks, culminating in a significant uptick of up to 21% in absolute metrics.
The Multimodal Architecture at the Heart of SpeechVerse’s Success
At the core of SpeechVerse lies a meticulously crafted multimodal architecture, comprising three indispensable components:
- Pre-trained Audio Encoder: Engineered to encode audio signals into compact feature sequences, this foundational element lays the groundwork for effective information extraction from audio inputs.
- 1-D Convolution Module: Serving as the linchpin for streamlining audio feature sequences, this module plays a pivotal role in optimizing data representation for subsequent processing stages.
- Pre-trained LLM: Harnessing the amalgamation of audio features and textual instructions, this sophisticated component orchestrates the execution of diverse tasks with precision and finesse.
Driving Innovation Through Model Variants
The research endeavor culminates in the development of three distinct variants within the SpeechVerse framework:
- Task-FT: A bespoke ensemble of models, meticulously tailored for individual tasks, epitomizing a granular approach towards task-specific optimization.
- Multitask-WLM: Symbolizing a paradigm shift, this unified multi-task model transcends conventional silos by amalgamating datasets across diverse tasks, thereby fostering synergistic learning and holistic comprehension.
- Multitask-BRQ: Representing the pinnacle of innovation, this variant harnesses the Best-RQ architecture for the audio encoder, amplifying the model’s efficacy in extracting salient audio features.
A Triumph of Innovation: SpeechVerse’s Unprecedented Performance
In an empirical showdown against conventional baselines, SpeechVerse emerges triumphant, outshining competitors on 9 out of 11 tasks. Notably, its robust performance extends beyond familiar domains, effortlessly tackling out-of-domain datasets, unforeseen prompts, and hitherto unexplored tasks.
Charting a Path Forward: The Vision for SpeechVerse’s Evolution
Looking ahead, the research team remains steadfast in their commitment to fortifying SpeechVerse’s capabilities. By prioritizing the decoupling of task specification from model architecture, SpeechVerse is poised to transcend boundaries, seamlessly adapting to novel tasks through natural language directives, sans the shackles of retraining.
Conclusion:
The advent of SpeechVerse marks a significant milestone in audio intelligence, heralding a paradigm shift in the market. Its unparalleled performance across diverse tasks and datasets underscores its potential to revolutionize industries reliant on audio data, offering a versatile framework for unlocking new insights and driving innovation. Businesses stand to gain a competitive edge by harnessing the transformative capabilities of SpeechVerse to extract actionable intelligence from audio sources.