
TL;DR:
- Language models used in user-centric AI applications need specialized training data.
- The self-talk methodology leverages two language models engaging in self-generated conversations.
- Structured prompting techniques convert dialogue flows into directed graphs.
- The resulting high-quality dataset refines agent training for precise task execution.
- Self-talk improves dialogue agents’ capabilities, focusing on specific tasks and workflows.
- It offers a cost-effective and innovative approach to training data generation.
Main AI News:
In the realm of user-centric applications, such as personal assistance and customer support, language models have emerged as the backbone of artificial intelligence’s rapid evolution. These versatile agents are entrusted with the pivotal task of comprehending and responding to a myriad of user queries and tasks. The key to their success lies in their agility to swiftly adapt to novel scenarios. Yet, the challenge persists – how to tailor these general language models to excel in specific functions, given the substantial demand for specialized training data.
Traditionally, the fine-tuning process of these models, often referred to as instructing tuning, relied heavily on human-generated datasets. While effective, this approach has grappled with limitations stemming from the scarcity of relevant data and the intricate nature of molding these agents to conform to complex dialogue workflows. These constraints have long hindered the creation of dialogue agents that are both responsive and task-oriented.
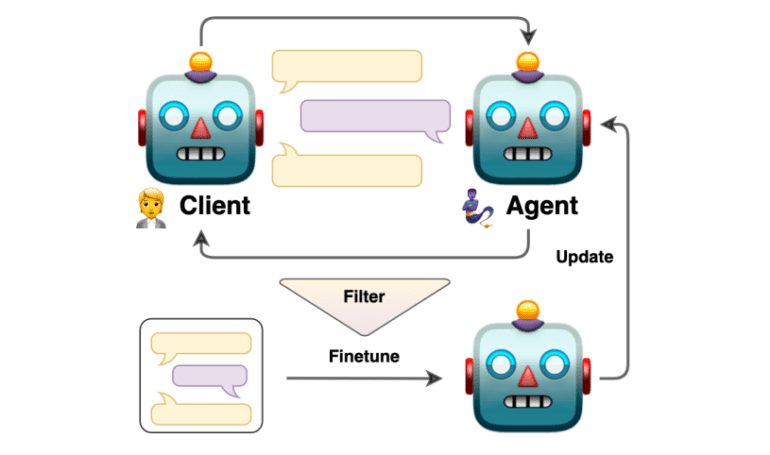
Enter a groundbreaking solution introduced by a collaborative team of researchers from the IT University of Copenhagen, Pioneer Centre for Artificial Intelligence, and AWS AI Labs – the self-talk methodology. This innovative approach revolves around harnessing the capabilities of two iterations of a language model engaged in a self-generated conversation. Each model assumes distinct roles within the dialogue, thereby not only enriching the training dataset but also refining the fine-tuning process, ensuring that agents adhere more effectively to specific dialogue structures.
At the heart of the self-talk methodology lies its structured prompting technique. In this ingenious approach, dialogue flows are transformed into directed graphs, meticulously guiding the interaction between the AI models. This structured exchange generates a plethora of scenarios, effectively simulating real-world discussions. The ensuing dialogues are subject to rigorous evaluation and refinement, resulting in the creation of a high-quality dataset. This dataset, in turn, becomes the cornerstone for training the agents, equipping them to master specific tasks and workflows with pinpoint precision.
The self-talk methodology’s efficacy shines brightly in its performance outcomes. This revolutionary technique has demonstrated immense promise in enhancing the capabilities of dialogue agents, particularly in their relevance to specific tasks. By emphasizing the quality of the generated conversations and employing stringent evaluation methods, the researchers have been able to isolate and harness the most effective dialogues for training purposes. The outcome? The development of dialogue agents that are not only more refined but also laser-focused on specific tasks.
Furthermore, the self-talk methodology stands out for its cost-effectiveness and innovative approach to training data generation. By sidestepping the reliance on extensive human-generated datasets, it offers a more efficient and scalable solution. As a result, the self-talk methodology marks a significant leap forward in the arena of dialogue agents, paving the way for the creation of AI systems that excel in handling specialized tasks and workflows with heightened effectiveness and relevance.
Conclusion:
The self-talk methodology represents a significant advancement in the development of AI dialogue agents. By addressing the challenges of specialized training data and enhancing the agents’ capabilities for specific tasks, it opens new opportunities in the market for more efficient and responsive AI systems, catering to a wide range of user-centric applications, and potentially reducing reliance on extensive human-generated datasets. This innovation has the potential to drive increased adoption of AI-powered dialogue agents in various industries, ultimately improving user experiences and efficiency.