
TL;DR:
- TIME-LLM is a groundbreaking framework for time series forecasting, developed in collaboration with Monash University and Ant Group.
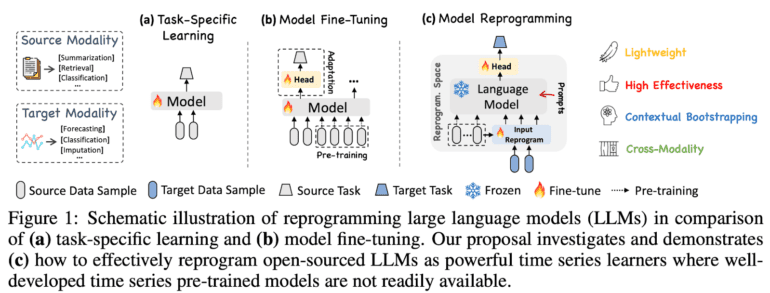
- It reprograms Large Language Models (LLMs) for forecasting without altering their core structure.
- The Prompt-as-Prefix (PaP) technique bridges the gap between numerical data and LLMs’ understanding, enhancing accuracy.
- TIME-LLM segments time series data into patches, maximizing the utilization of LLMs’ knowledge.
- Empirical evaluations show that TIME-LLM outperforms specialized models in various scenarios.
- This innovation opens new possibilities for repurposing LLMs in data analysis and beyond.
Main AI News:
In the ever-evolving world of data analysis, TIME-LLM has emerged as a game-changing framework, redefining how we approach time series forecasting. This groundbreaking innovation, developed through a collaboration between prestigious institutions such as Monash University and Ant Group, represents a departure from conventional methods. TIME-LLM harnesses the power of Large Language Models (LLMs), traditionally utilized in natural language processing, to predict future trends in time series data. Remarkably, it achieves this without altering the fundamental structure of LLMs, offering a versatile and efficient solution to the forecasting challenge.
At the core of TIME-LLM lies a pioneering reprogramming technique known as Prompt-as-Prefix (PaP), which bridges the gap between numerical data and LLMs’ textual comprehension. PaP enriches input with contextual cues, enabling the model to accurately interpret and forecast time series data. This approach leverages the inherent pattern recognition and reasoning capabilities of LLMs while eliminating the need for domain-specific data. The result is a new standard for model generalizability and performance.
The methodology behind TIME-LLM is both intricate and ingenious. It segments input time series into discrete patches and applies learned text prototypes to each segment, transforming them into a format comprehensible by LLMs. This process maximizes the wealth of knowledge embedded in LLMs, enabling them to extract insights from time series data as if it were natural language. Task-specific prompts further enhance the model’s ability to make nuanced predictions, providing a clear directive for the reprogrammed input transformation.
Empirical evaluations of TIME-LLM have consistently demonstrated its superiority over existing models. Notably, the framework excels in both few-shot and zero-shot learning scenarios, outperforming specialized forecasting models across diverse benchmarks. This achievement is particularly remarkable given the variability of time series data and the complexity of forecasting tasks. TIME-LLM’s adaptability shines through, enabling precise predictions with minimal data input, a feat that traditional models often struggle to accomplish.
TIME-LLM’s success extends beyond the realm of time series forecasting, opening up exciting possibilities in data analysis and beyond. This research showcases the effective repurposing of LLMs for tasks outside their original domain, paving the way for harnessing LLMs’ reasoning and pattern recognition capabilities in various data-related fields, ushering in a new era of exploration and innovation.
Conclusion:
TIME-LLM’s groundbreaking approach to time series forecasting unlocks the full potential of LLMs, offering unparalleled accuracy and adaptability. This innovation has the potential to disrupt the market by revolutionizing data analysis and expanding LLMs’ applications across various domains. Businesses that adopt TIME-LLM can gain a competitive edge in making precise predictions and extracting insights from diverse data sources, positioning themselves as leaders in the data-driven era.