
- Toyota Research Institute introduces SUPRA, a novel methodology enhancing transformer efficiency with recurrent neural networks (RNNs).
- SUPRA combines the strengths of transformers and RNNs, achieving competitive performance benchmarks at reduced computational cost.
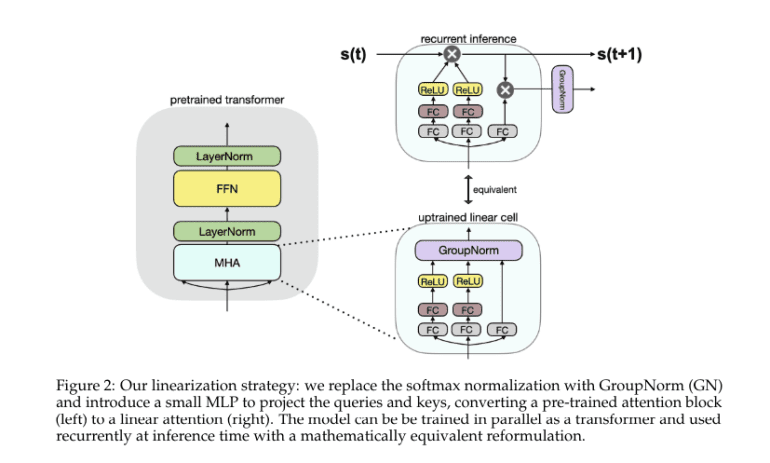
- The methodology involves uptraining established transformers like Llama2 and Mistral-7B, replacing softmax normalization with GroupNorm and incorporating a compact multi-layer perceptron (MLP) for query and key projection.
- Rigorous benchmark assessments demonstrate SUPRA’s remarkable performance across various NLU benchmarks, surpassing previous models on tasks like HellaSwag, ARC-E, ARC-C, and MMLU.
- Despite encountering minor performance fluctuations in long-context tasks, SUPRA consistently delivers resilient outcomes within its training context length.
Main AI News:
In the realm of natural language processing (NLP), neural networks, particularly transformer models, have spearheaded remarkable advancements. Despite their prowess, these models grapple with significant challenges stemming from their intensive memory and computational demands, especially in scenarios requiring extensive contextual analysis. This persistent predicament underscores the imperative for innovative solutions that balance performance with resource efficiency.
At the core of transformer models lies a dilemma: their formidable memory and processing requisites. While excelling in NLP tasks, their practicality diminishes in resource-constrained environments. Addressing this predicament necessitates the development of models with reduced computational overhead yet commensurate performance with existing benchmarks. Overcoming this hurdle is pivotal for broadening the applicability and accessibility of contemporary NLP technologies across diverse domains.
Recent studies have explored various avenues to mitigate transformer inefficiencies. Initiatives like Linear Transformers seek to augment efficiency vis-a-vis softmax transformers. Models such as RWKV and RetNet showcase competitive capabilities with their linear attention mechanisms. Meanwhile, state-of-the-art architectures like H3 and Hyena integrate recurrent and convolutional networks to tackle prolonged sequence tasks. Techniques like Performers, Cosformer, and LUNA zero in on refining transformer efficiency, while the Griffin model amalgamates sliding window and linear attention strategies.
In a groundbreaking endeavor, researchers from the Toyota Research Institute have introduced Scalable UPtraining for Recurrent Attention (SUPRA), a pioneering method to transform pre-trained transformers into recurrent neural networks (RNNs). This innovative approach harnesses the rich pre-training data of transformers while implementing a linearization technique that substitutes softmax normalization with GroupNorm. SUPRA stands out by synergizing the strengths of transformers and RNNs, achieving competitive performance benchmarks at a fraction of the computational cost.
The SUPRA framework entails uptraining established transformers like Llama2 and Mistral-7B, wherein softmax normalization is supplanted by GroupNorm alongside a compact multi-layer perceptron (MLP) for query and key projection. Leveraging the RefinedWeb dataset comprising 1.2 trillion tokens, models underwent training and fine-tuning via a customized iteration of OpenLM, with evaluations conducted using the Eleuther evaluation harness across standard NLU benchmarks. This methodology empowers transformers to operate recurrently and efficiently, adeptly managing tasks spanning short and extended contextual ranges.
In rigorous benchmark assessments, SUPRA showcased remarkable performance across diverse metrics. Surpassing RWKV and RetNet on the HellaSwag benchmark, it garnered a notable score of 77.9 compared to 70.9 and 73.0, respectively. Moreover, the model exhibited robust performance on other benchmarks, securing scores of 76.3 on ARC-E, 79.1 on ARC-C, and 46.3 on MMLU. Impressively, training requisites stood at a mere 20 billion tokens, significantly lower than alternative models. Despite encountering minor performance fluctuations in protracted contextual analyses, SUPRA consistently delivered resilient outcomes within its designated training context length.
Conclusion:
The introduction of SUPRA by Toyota Research Institute represents a significant breakthrough in transformer efficiency, offering a promising solution to the industry-wide challenge of balancing performance with computational resources. This innovation has the potential to revolutionize the market landscape by enabling more accessible and efficient deployment of NLP technologies across diverse domains. Organizations leveraging SUPRA stand to gain a competitive edge through enhanced performance and resource optimization.