
- UC Berkeley, ICSI, and LBNL developed LLM2LLM to enhance LLM performance in data-constrained scenarios.
- LLM2LLM diverges from traditional data augmentation methods by targeting specific model weaknesses.
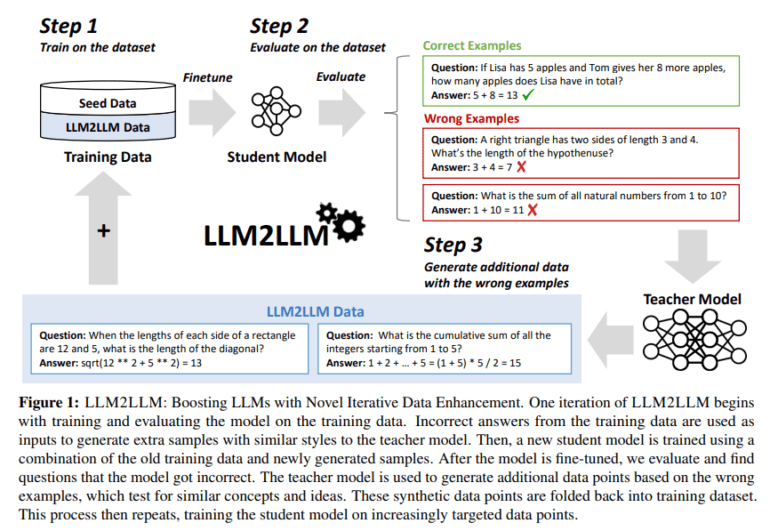
- It employs an iterative process involving a mentor and pupil model to refine performance.
- Synthetic data generated by the mentor model is used to train the pupil model on identified weaknesses.
- Testing on various datasets showcased significant performance improvements, up to 32.6%.
Main AI News:
Pioneering advancements in natural language processing, large language models (LLMs) represent a pivotal stride in machine comprehension and text generation. However, the constrained availability of task-specific training data often hampers the full utilization of LLMs, curtailing their effectiveness across diverse domains.
Enter LLM2LLM, conceived by a collaborative research effort from UC Berkeley, ICSI, and LBNL, presenting a revolutionary methodology to bolster LLM capabilities within low-data environments. Departing from conventional data augmentation strategies involving basic alterations like synonym substitutions or paraphrasing, LLM2LLM introduces a sophisticated, iterative paradigm targeting the core weaknesses of models, thereby fostering a continuous improvement loop.
The essence of LLM2LLM lies in its interactive interplay between two LLMs: a mentor model and a pupil model. Initially, the pupil model undergoes fine-tuning on a restricted dataset, followed by meticulous evaluation to pinpoint areas of prediction inaccuracies. These identified weak spots serve as crucial focal points for the mentor model, which generates synthetic data replicating these challenging instances. Subsequently, this synthesized dataset is utilized to refine the pupil model, directing its training efforts towards rectifying previously acknowledged deficiencies.
What distinguishes LLM2LLM is its precision-focused, iterative data augmentation strategy. Rather than indiscriminately expanding the dataset, it strategically crafts new data tailored to address the model’s specific shortcomings. Validated against the GSM8K dataset, LLM2LLM demonstrated an impressive 24.2% enhancement in model performance. Likewise, substantial improvements were observed on the CaseHOLD dataset, with a 32.6% boost, and on SNIPS, registering a notable 32.0% increase.
Conclusion:
The introduction of LLM2LLM represents a significant advancement in the field of natural language processing. By effectively addressing the limitations posed by data scarcity, this innovative methodology opens up new avenues for the application of large language models across diverse domains. Companies investing in NLP technologies can leverage LLM2LLM to enhance their models’ performance even in low-data environments, potentially gaining a competitive edge in delivering more accurate and contextually relevant language processing solutions.