
TL;DR:
- Text-to-X models have advanced, with a focus on text-to-image models.
- Text-to-video models aid in generating realistic videos from text prompts.
- Text-to-3D generation has gained attention in computer vision and graphics.
- Neural Radiance Fields (NeRF) enable the rendering of complex 3D scenes.
- Challenges arise in combining text-to-3D models with NeRF, including 3D incoherence.
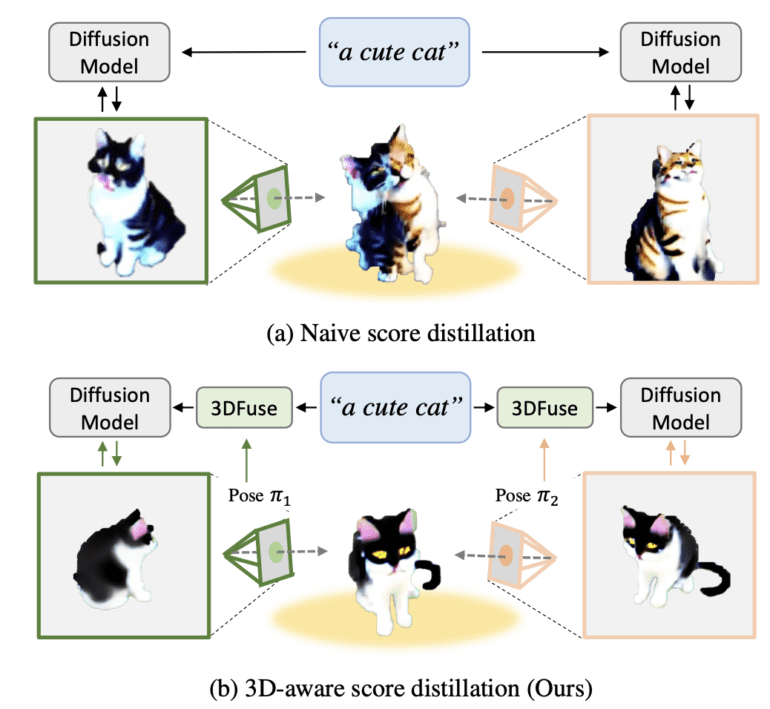
- 3DFuse bridges the gap by imbuing 3D awareness into diffusion models.
- 3DFuse incorporates semantic code and depth maps to inject 3D information.
- A sparse depth injector rectifies errors in predicted 3D geometry.
- 3DFuse optimizes NeRF for view-consistent text-to-3D generation, achieving significant improvement in quality and consistency.
Main AI News:
In the realm of Text-to-X models, remarkable progress has been made, particularly in the domain of text-to-image models. These cutting-edge models have the ability to generate stunningly realistic images based on textual prompts. While image generation remains a vital component, it is crucial to acknowledge the existence of other Text-to-X models that play indispensable roles in various applications. Among these is the realm of text-to-video models, which endeavor to create lifelike videos from given text prompts, effectively expediting content creation processes.
However, an emerging field that has captured the attention of computer vision and graphics experts is text-to-3D generation. Though still in its nascent stages, the capacity to transform textual input into lifelike 3D models has engendered significant interest from both academic researchers and industry professionals. This transformative technology holds immense potential for revolutionizing numerous industries, attracting multidisciplinary experts who closely monitor its ongoing advancements.
Recently, a groundbreaking approach called Neural Radiance Fields (NeRF) has emerged, enabling the high-quality rendering of intricate 3D scenes using either a collection of 2D images or a sparse arrangement of 3D points. To enhance the capabilities of text-to-3D models, several methods have been proposed, combining them with NeRF to produce visually pleasing 3D scenes. However, these approaches often suffer from distortions, artifacts, and sensitivity to text prompts and random seeds.
A prevalent issue encountered is the problem of 3D incoherence, whereby the rendered 3D scenes exhibit geometric features that repeatedly appear from a frontal viewpoint at various angles, resulting in substantial distortions. This shortcoming arises due to the lack of 3D awareness within the prevailing 2D diffusion models, particularly regarding camera pose.
What if there was a solution that successfully combined text-to-3D models with the advancements in NeRF, resulting in highly realistic 3D renders? Enter 3DFuse, a game-changing middle-ground approach.
3DFuse bridges the gap by integrating a pre-trained 2D diffusion model with 3D awareness, making it apt for achieving 3D-consistent NeRF optimization. This pioneering approach seamlessly infuses 3D awareness into pre-trained 2D diffusion models, opening up new possibilities for enhanced text-to-3D generation.
The process begins with the sampling of semantic code, which expedites the identification of semantic elements within the generated scene. This semantic code comprises the generated image and the provided text prompt for the diffusion model. Once this crucial step is completed, the consistency injection module of 3DFuse utilizes the semantic code to acquire a viewpoint-specific depth map by projecting a coarse 3D geometry corresponding to the given viewpoint. Leveraging an existing model, this depth map is generated. Subsequently, the depth map and the semantic code synergistically inject 3D information into the diffusion model.
A potential challenge arises as the predicted 3D geometry is susceptible to errors, potentially impacting the quality of the resulting 3D model. Consequently, this issue must be effectively addressed before progressing further within the pipeline. To mitigate this concern, 3DFuse introduces a sparse depth injector, adept at rectifying problematic depth information implicitly.
By distilling the score of the diffusion model, which ensures the generation of 3D-consistent images, 3DFuse achieves stable optimization of NeRF for view-consistent text-to-3D generation. Remarkably, this framework surpasses previous endeavors in terms of both generation quality and geometric consistency, marking a significant advancement in the field.
Conclusion:
The emergence of 3DFuse and its ability to combine text-to-3D models with 3D awareness and NeRF optimization represents a significant advancement in the market. This innovative approach opens up new possibilities for industries reliant on realistic 3D visualizations, such as gaming, architecture, virtual reality, and product design. With improved generation quality and geometric consistency, 3DFuse has the potential to revolutionize content creation processes and enhance the immersive experiences delivered to end-users. As this technology continues to evolve, businesses should closely monitor its developments to capitalize on the transformative power of 3D-generated content.